In this lecture, we will discuss the training phase of activity recognition; the complete machine learning task of building a classification system that can automatically infer your activity (e.g., standing, walking, running) breaks down into two sequential phases:
In what follows, we only discuss the training phase where we collect data and create a classification model. I will show how to collect activity data using MyRuns Data Collector and teach you how to play with Weka GUI to train your own classifier.
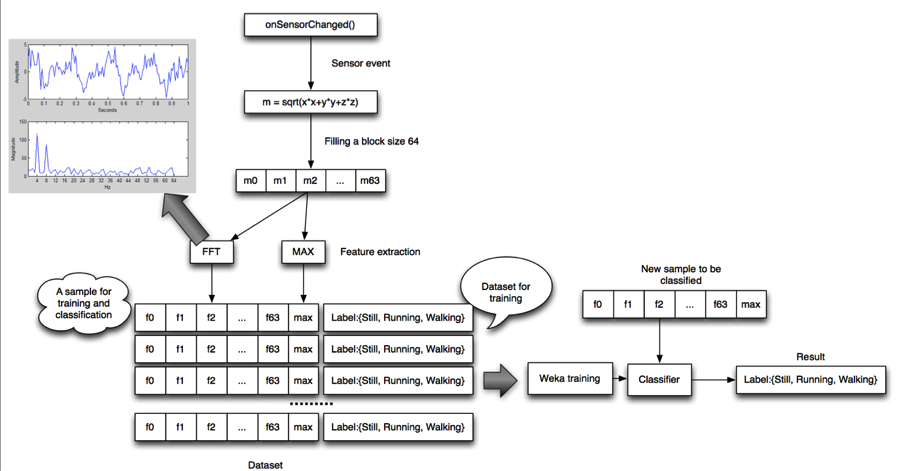
The training phase is illustrated in the figure below -- don't panic: we do not expect you to write low-level signal processing functions such as compute the FFT -- we give out code to do that. The training phase boils down to the following steps at a high level:
Important. When you collect and label activities -- like walking, running -- make sure that you walk, run, etc. for a least 3 minutes for each activity. By doing this you will have more data for each activity class and a better classifier -- WekaClassifier. Makes sense right? The more data the less confused the classifier will be. If you only have a little data it will confuse classes -- standing with walking, walking with running. It is true the classifiers do get confused and that is OK. But the more data the less they get confused. You might collect less than 3 minutes per class when you are debugging but for your final polished product the more data the better. And there is nothing stopping your re-creating the classifier and just popping it into WekaClassifier.java.
Let’s discuss this diagram in a little more. Note, there is a lot of code reuse between coding the collector (which used for training phase) and the classification phase which supports by MyRuns automatic mode. But for the training phase you do not have to write code -- as indicated in the steps above.
In the training phase a method called onSensorChanged() produces sensor samples (x, y, z) in a time series (each time onSensorChanged is called), which computes m (magnitude) from the sensor samples. The workflow buffers up 64 consecutive magnitudes (m0..m63) before computing the FFT for each of the magnitudes (f0..f63) – each of these features is called an FFT coefficient; e.g., f0 and f63 are the low and highest frequency coefficients, as shown in the diagram.
As shown in the upper left of the diagram, FFT transforms a time series of amplitude over time to magnitude (some representation of amplitude) across frequency; the example shows some oscillating system where the dominant frequency is between 4-8 cycles/second called Hertz (H) – imagine a ball attached to an elastic band that this stretched and oscillates for a short period of time, or your gait while walking, running -- one could look at these systems in the time and frequency domains. The x,y,z accelerometer readings and the magnitude are time domain variables. We transform these time domain data into the frequency domain because the can represent the distribution in a nice compact manner that the classifier will use to build a decision tree model. For example, the rate of the amplitude transposed to the frequency domain may look something like the figure bottom plot -- the top plot is time domain and the bottom plot a transformation of the time to the frequency domain. Cool hey.
The training phase also stores the maximum (MAX) magnitude of the (m0..m63) and the user supplied label (e.g., walking) using the collector. The individual features are computed magnitudes (f0..f63) and MAX magnitude and label are added: collectively, we call these features the feature vector and again it comprises:
magnitudes (f0..f63), MAX magnitude, label. Because the user can collect a small or larger amount of data, the size of the feature vector will vary (and the size and complexity of the generated WekaClassifier class will change). The longer you collect data the more feature vectors accumulated. Once the user has stopped collecting training data using the collector tool -- we move to WEKA to carry on the workflow. The output of the collector is features.arff and this file is the input to the WEKA tool. Get it? You need to make sure you install WEKA to keep moving onto the next step in the workflow.
To complete the training phase we run Weka GUI to generate the classifier. The creation of the classifier is the completion of the training phase. As mentioned before we add the generated WekaClassifier to the WekaClassifier.java file in your MyRuns5 project.
While we focus on the training phase in this lecture the diagram also shows the classification phase. MyRuns uses exactly the same workflow of the training phase in terms of computing the feature vectors (sampling x,y,z, computing the magnitudes – and MAX – and FFT coefficients) but this time there is no user supplied label as in the collector. The classification phase does not need the user to supply a label because it has trained a model (WekaClassifier) that can infer the label (e.g., walking) from the feature vectors. The pipeline of computing the feature vectors is simply shown in the diagram as new samples to be classified that is fed into the Classifier (WekaClassifier) – the result is a label (e.g., running). So in the classification phase our running MyRuns5 app sets the accelerometer data (x, y, z) computes the feature vector and passes that to the classifier WekaClassifier, and as a result your phone can now automatically infer what you are doing!
We now discuss the project design for the collector. As shown below the collector consists of the CollectorActivity, Globals (data) and SensorService. The project also shows the FFT.java and the Weka.jar. Again, we give you the source code for the collector and much of the processing used during the real-time classification can be also see here in the collector which is used as part of off-line training phase.
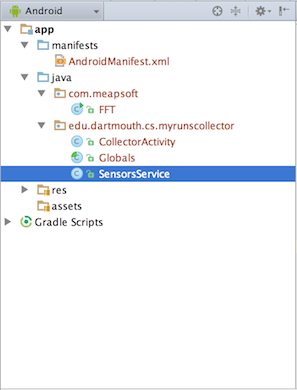
The goal of the collector is to collect sensor data for four different activity classes (viz. standing, walking, running, others). As I demoed in class you need to collect data for the at least three of the classes (viz. standing, walking, running). The user (read you) selects an activity (thereby providing the training phase the label it needs to associate with the data it’s about to collect – this is called supervised learning in Machine Learning parlance). Once an activity is selected (e.g., walking) the user clicks “start collecting” and starts to walk around for at least 3 minutes. Note, that once the user selects start collecting “Delete data” button (discussed below) is disabled – you don’t want to accidentally delete the data. The user repeats this for each of the activities --- pressing stop at the end of the activity collection phase and then selecting a new activity and starting to collect again – so, yes, in the case of running you need to take a 3 minute run (tip: while debugging you don’t need to run during code updates – simple emulate standing, walking and running by shaking the phone in your hand; once you have solid code then go for the real run, etc.).
The delete button removes the data, which is stored in a file on the phone (called features.arff). If you want to start all over hit delete before starting else the new collected data will be appended to the end of the file. You could collect multiple instances of training data – go for multiple runs, walks and different times and it should all be accumulated in the same file. The collector implements the training phase shown in the diagram and discussed in the section above. The result of the collector phase is the creation of a Weka formatted features.arff file. So the collector needs to be able to collect accelerometer samples, compute the magnitudes and use the FFT.java class to compute the coefficients, etc. to produce the feature vectors. The weka.jar APIs are used to format the feature vectors into to the correct format for the Weka tool that produces the classifier, as discussed in the next section.
Next, we need to upload the saved data to laptop. File Explorer in your Android Device Monitor helps to do that. You can access your Android Device Monitor by clicking the android robot icon as following.

By selecting your device on the left, your device storage will be shown on the right. Click through mnt-> shell -> emulated -> 0 -> Android -> data -> edu.dartmouth.cs.myrunscollector -> files, you will see the collected feature file features.arff. 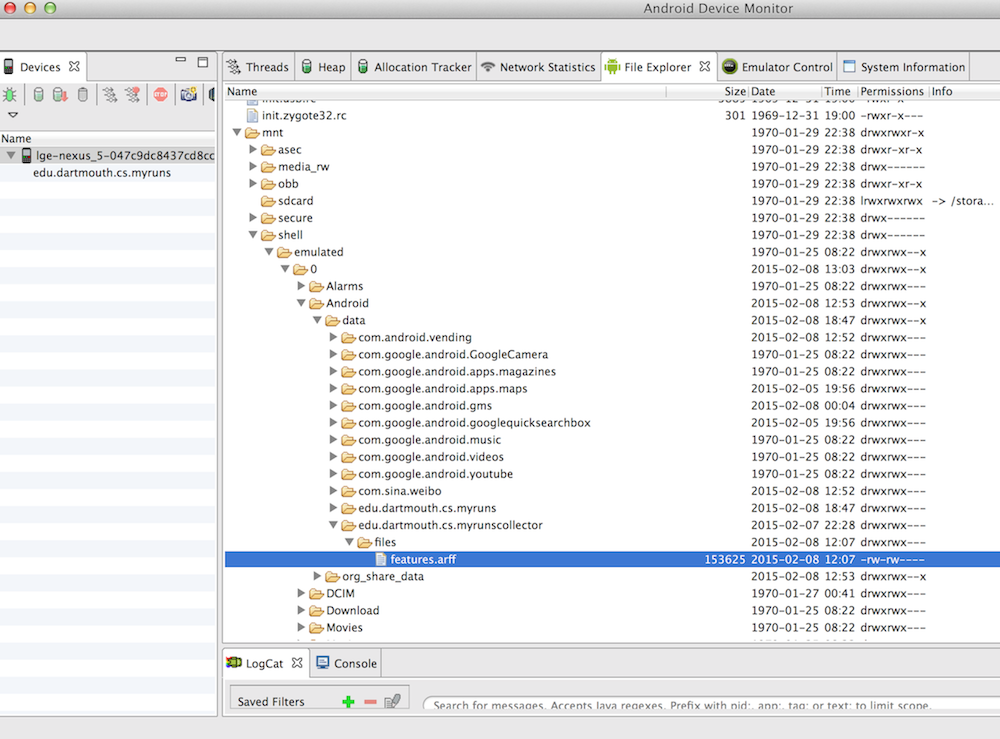
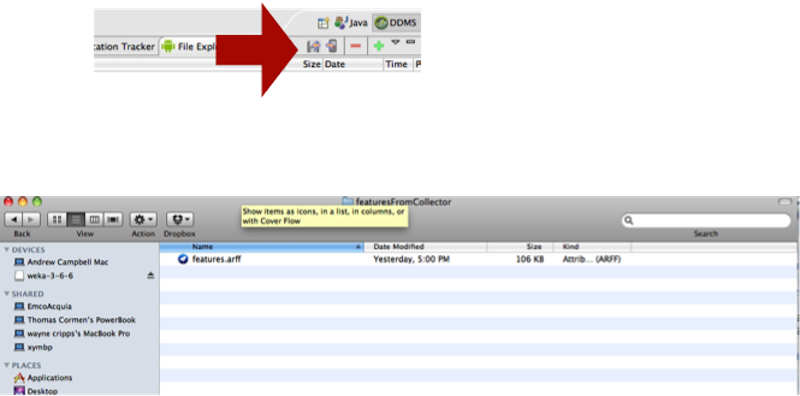
To upload this file to your computer, you need to highlight the file (features.arff) and click upload – red arrow points to it in the DDMS view.
We now discuss how to use the data collected by the data collector as input to the WEKA tool to generate the WekaClassifier java class based on the J48 decision tree (a ML algorithm).
Frist you need to install WEKA. Once the features.arff file is uploaded, my mac knows it is a Weka file as shown with the WEKA bird icon on the file. Clearly you need to have downloaded and installed Weka for the system to recognize the file extension. Therefore, you need to install Weka:
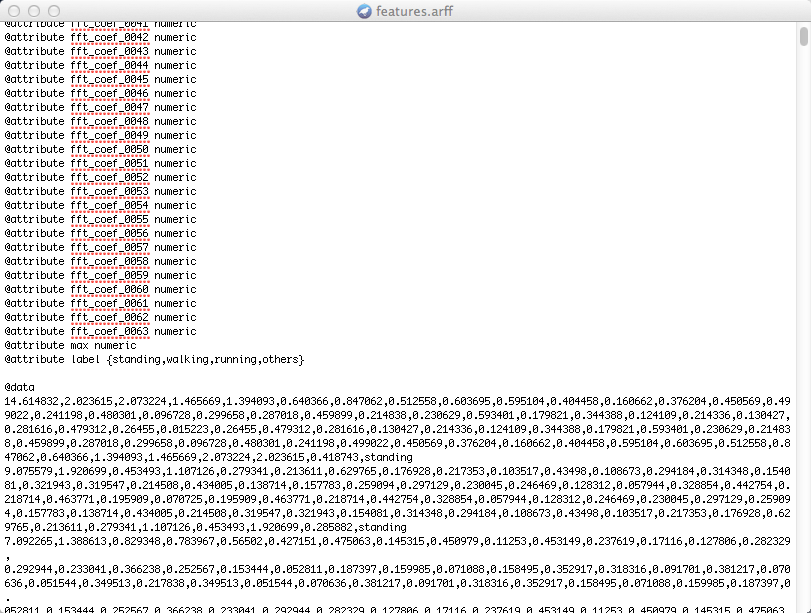
Once WEKA is installed on your laptop and the features.arff file uploaded to your laptop then WEKA can generate the classifier. BTW, if you open features.arff using your favorite text editor you will see the Weka format of the file - interesting hey. The layout of the file makes complete sense. The first part of the file is the specification followed by the feature vector as shown figure below. The more time you send collecting data the feature vectors you will see the file.
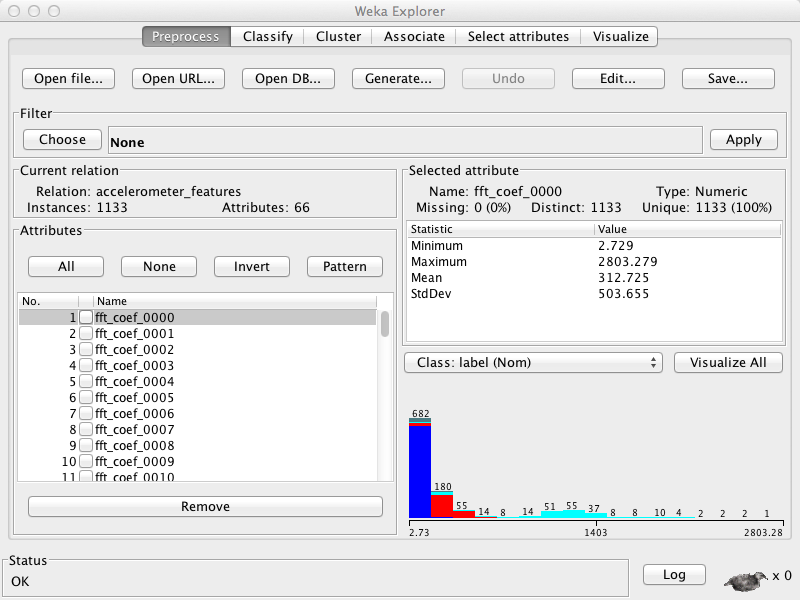
If you click on features.arff the WEKA will fire up automatically with the following window, as shown below.
Select the Classify option – and then select Choose and select the J48 decision tree (folder weka->classifiers->trees->j48) is selected and then select More options .. to specify the source code name (WekaClassifier) of the classifier object.
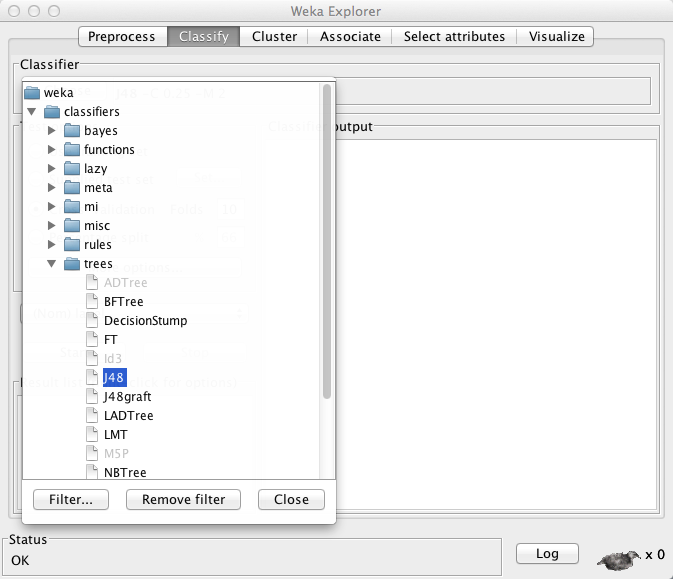
So we name the classifier object – output source code WekaClassifier.
Now we are ready to generate the WekaClassifier classifier – and its java class implementation. Click Start to generate the java class code for the classifier (and, BTW, a lot of other interesting information including the confusion metric I showed and discussed in class). In essence WEKA takes the training data you supplied in features.arff to train a J48 decision tree classifier -- it spits out the java code for the classifier. The confusion metrics indicates when the classifier confused one class over another; for example, the confusion metric tells us that standing (i.e., still) gets confused with the walking activity in 4 cases and with running in 1 case.
If you look at the code produced by WEKA you see a bunch of if-then statements (see the code below). It is complete and you will not be able to make sense of it. To understand the code take the CS machine learning class. Until then consider is WEKA magic. This classifier is a personal classifier based only on your data. If you do this in the wild you would get a large corpus on training data from a large number of people. Why do that? Because you would like your app to work for not just you but a large population of users.
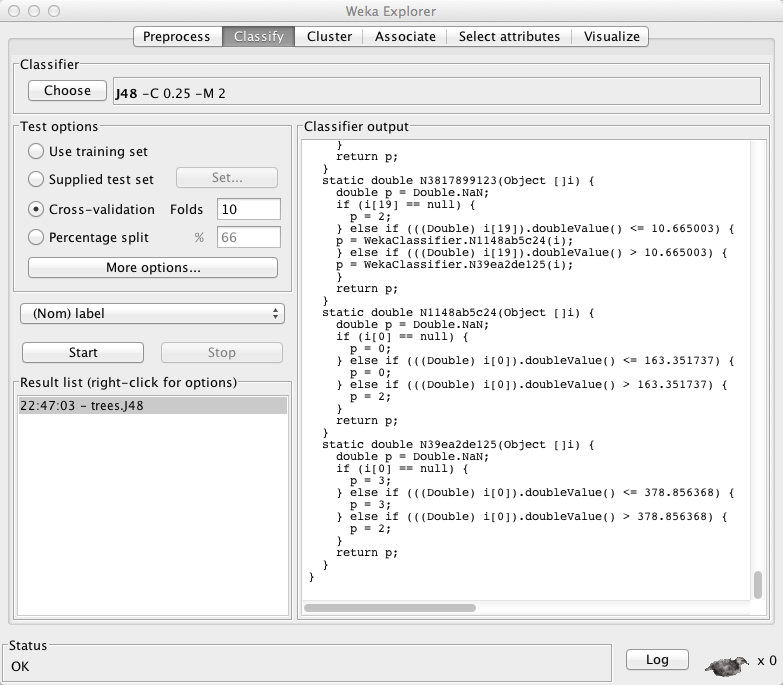
The last thing you have to do is cut and paste the class WekaClassifier{ ...} (and only the java code -- not the other stuff like the confusion metric) -- again, only the java code; for example here is the code I trained and popped into WekaClassifier.java
class WekaClassifier {
public static double classify(Object[] i)
throws Exception {
double p = Double.NaN;
p = WekaClassifier.N36673c9f0(i);
return p;
}
......
static double N1901b54e3(Object []i) {
double p = Double.NaN;
if (i[64] == null) {
p = 2;
} else if (((Double) i[64]).doubleValue() <= 4.573082) {
p = 2;
} else if (((Double) i[64]).doubleValue() > 4.573082) {
p = 1;
}
return p;
}
}OK. Now you have completed the training phase and imported your classifier into your project. Now you have to implement the rest of the classification pipeline -- it's described in the lab write up for MyRuns Design Doc