GPS receivers are widespread in mobile devices today, but because of their inherent inability to detect satellite signals indoors, they are poor choices for localization in these environments. Wi-Fi positioning is often used as an alternative in these situations, but its accuracy can suffer greatly from variations in signal strength and obstacles. Furthermore, the technique's accuracy is limited even in ideal conditions, thus making it unsuitable for high-precision indoor localization. It is however often desirable to be able to position devices accurately indoors. Augmented reality applications, for example, would need this. Also, mapping applications like the one on the iPhone might want to provide bearings for their users in large indoor locations like malls or department stores.
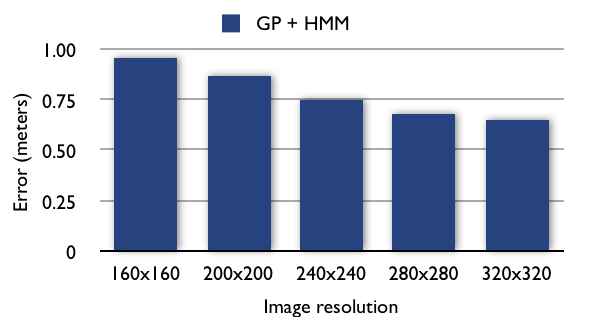
We use Gaussian processes on GIST image features in order to determine a user's location from image data alone. As these features are high-dimensional vectors, first we convert high resolution images(1600*1200) to lower resolution ones. Then we apply PCA as an intermediate step to reduce the feature dimensions before GP. We also smooth the resulting output time series using a hidden Markov model(HMM), which enforces constraints on the trajectory of the movement of the people.
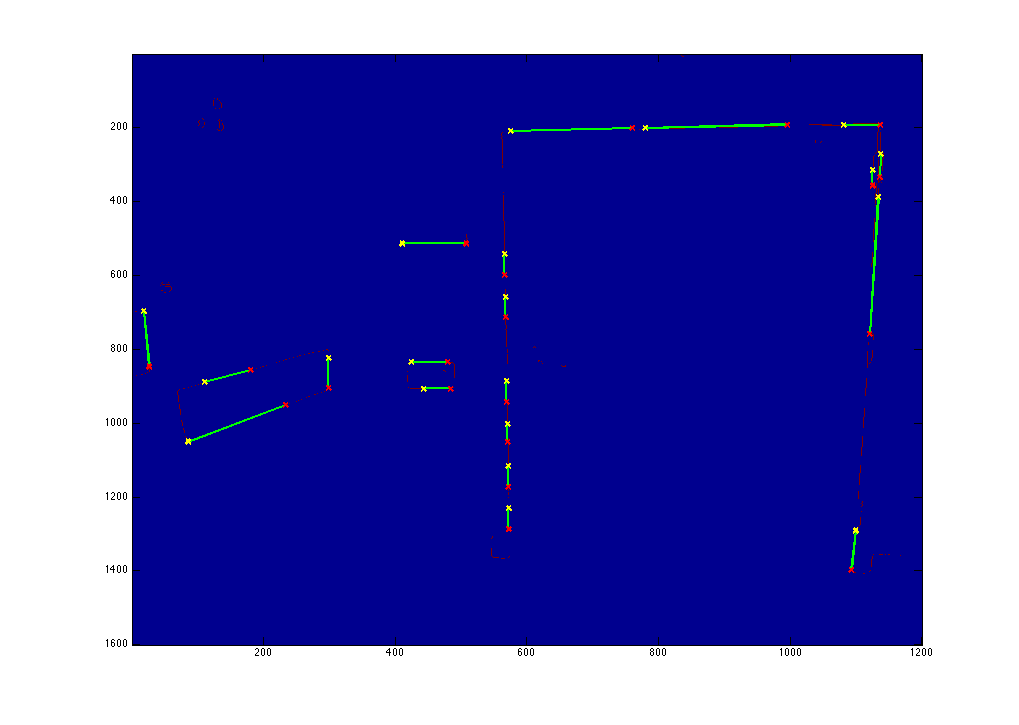
To attempt to model the camera pose, we first took each image, converted it to the LAB color space, in which the L channel closely approximates luminance as perceived by the human eye, and applied a Canny edge filter to L. We then applied a Hough transform (with each line parametrized by polar coordinates) and found peaks in Hough space to detect lines in the image. We then find all pairwise intersection points and attempt to cluster them into three clusters, to find vanishing points. We hypothesize that the coordinates of these vanishing points will be strongly correlated with the orientation of the camera, assuming the scene in the image contains many strongly linear features that are orthogonal to one another in space (i.e., not in the 2d projection in the image).
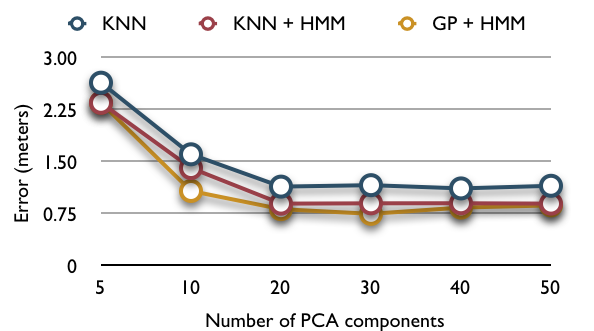
We took several hundred photographs of the hallways of Sudikoff under different conditions. Our early images were intended for a separate labeling step, but for our later images we captured the images in a predictable sequence to save us from having to label them in a separate step. To evaluate our technique, we compared it against a simple k-nearest-neighbor model. We tried k-NN both with and without the same HMM for temporal smoothing. We also applied PCA to the input of k-NN for fair comparison.
We were unable to get meaningful results out of the vanishing point clustering, but the Hough output on its own worked.

Our joint PCA + GP + HMM technique outperforms the same treatment applied to k-NN(k=1), but not by a substantial margin. We do nonetheless achieve error rates small enough to allow a high-precision indoor localization system, given sufficient training data. We believe a significant factor limiting the performance of the GP to be the relative discontinuity of the GIST feature set we used. The features are not highly smooth among image taken from nearly by locations, especially around the corner. Moreover, the variance of viewing angle and camera pose in the training set also contribute to this problem. A SIFT- or SURF-based system is attractive but not directly usable with these techniques because they generate variable-dimension feature vectors. Although our datasets did not contain examples to test this on, we predict that GP's more sophisticated approach of modeling the underlying function would be more robust to anomalous objects and configurations of the building (people walking around, doors open and closed, lighting conditions). Although the second stage HMM reduces the error over a series of images. It does not work seamlessly with GP. The output of GP are real numbers, but in our naive implementation the HMM takes discrete observations. We have to round the output of the GP and feed the data into HMM. The rounding also introduces some error.
As mentioned before, the images we collected and feature we use are not nicely fit the smoothness assumption of GP. We intend to adapt our system to use more training samples or even video sequence which is more "continuous". We will try SIFT or SURF features, which are robust to scale and rotation, possibly by binning the variable-length features or by applying edit distance-like techniques to compare two images. We also intend to explore the issue of camera pose estimation in more detail, using more sophisticated vanishing point detection techniques. A nice property of GP is that it give the prediction as well as the confidence level (variance). Currently, we only use the predictions without looking at the confidence level. It would be good to take the confidence level into consideration.
Closely related to our work is that of Dieter Fox, who uses GP on Wi-Fi signal strengths to achieve good indoor localization performance. The IM2GPS project at CMU has a similar goal to ours, but attempts to position a single photograph globally based on a large database of images. We believe that while this project is interesting, specific domain knowledge about indoor locations can improve performance and should be explored separately from outdoor situations.