
As the readership of blogs and other regularly updated websites has increased over the last few years , many people have begun reading feeds using syndication formats such as RSS and Atom. One common problem faced by users of RSS readers is "information overload": while a person may like to be updated with stories from a variety of different feeds, the sheer number of regular news articles and blog entries available makes it difficult to sift out the articles which are interesting and relevant to the user from the "junk".
To combat this problem and make the use of an RSS reader more satisfying, I propose using support vector machines (SVM) to classify RSS stories based on their "interestingness". While other RSS aggregators have used Naive Bayesian classifiers and other techniques to filter stories (1), there are not any major RSS readers which use SVMs. Due to their speed and their proven strength on text classification tasks, I believe that SVMs would be a useful way to determine a user's preferences in news stories from ratings of stories which have already been read.
RSSaurus, the RSS aggregator I built, transformed user-provided ratings into story recommendations through the following steps:
To handle the downloading and parsing of RSS and Atom feeds, I used the ROME library for Java, which provides a number of tools for the manipulation of syndication formats. This allows the aggregator to break an RSS item down into HTML content, title and author information, and links, which are then displayed for the user to read.
Once the RSS stories have been downloaded and displayed, the user may read the stories, follow the links, and classify the story based on whether they find it interesting or not. The application will store all the rated stories and associated ratings between uses.
Once a sufficient number of ratings have been collected, an SVM may be trained to filter stories based on the user's tastes. To begin, the application creates a dictionary of words to be used as the feature set. Each individual training entry is parsed into tokens with common punctuation marks excluded. To keep HTML tags out of the dictionary, tokens which contain the symbols "&","=","<", and ">" are excluded. All the remaining tokens are added to the dictionary. Finally, all words which occur less than 4 times in all the training entries are removed, to keep the dictionary size manageable.
For each entry, a feature vector was calculated using the tfidf function:
tfidf(tk, dj) = #(tk , dj) * log(|Tr| / #Tr(tk))
where #(tk , dj) is the number of times tk occurs in entry dj, |Tr | is the total number of entries, and #Tr(tk) is the number of entries which contain tk. (3). I also tried using the the tfidf-Global function, which replaces #Tr(tk) with the total number of occurences of tk in all entries and simply using the frequency of the word in the document. The tfidf function performed better than either of these, which led me to choose it for the final application.
The application uses the feature vectors calculated in the previous step to train a linear support vector machine with an implementation of John Platt's sequential minimal optimization algorithm (4). Because there were relatively few training examples per subject and the feature vectors had a high dimensionality, there are linear SVMs a good choice. Moreover, linear SVMs are faster (an important feature in an application being used in real time) and easier to implement than kernel SVMs. I also tried using an radial basis function kernel, which gave comparable results, but took far longer to train.
Once a support vector machine has been trained for a user, the application will predict whether a user will like new stories based on the SVM's classification. The user may then reclassify stories and train again.
To test the performance of my application, I recruited four different test subjects, and asked them to classify 150 news stories combined from a number of different blogs and websites (The Huffington Post, The New York Times, perezhilton.com, and engadget.com, to name a few). I told the subjects to rate based on "whether they would like to read more similar articles." Additionally, to artificial subjects were created to determine if the application could make discriminations based on specific content criteria (filtering food blogs from news blogs, and technology blogs from celebrity gossip blogs). For these, two exemplar blogs were chosen for the each category, and all entries from blogs in the same category were given the same rating. For example, for the "Food Vs. News" discrimination task, all the entries from Serious Eats and Epicurious.com were given a thumbs-up, while all entries from The New York Times and The Huffington Post were given a thumbs-down.
Each set of classified entries was divided into a training set (two-thirds of the set) and a testing set (one-third of the set). Training and test errors were recorded.
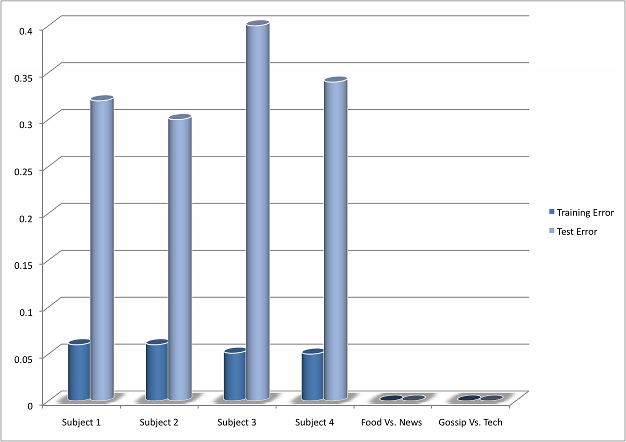
Given the complex nature of personal taste and the small size of my training set, I pleasantly surprised with the results I received. With a training set of 100 entries, the SVM was able to predict a subject’s rating with an accuracy of 65- 70% on average. Moreover, the SVM performed very well on the specific criteria discrimination tasks, with perfect performance on the test set for both the "Food vs. News" and "Gossip vs. Tech" sets. When these classifiers were applied to other RSS feeds, visual inspection showed that the classifiers gave results that made intuitive sense (for example, a news item about Barrack Obama's visit to a D.C. area burger joint was classified under "Food", a tech blog entry that mentioned Angelina Jolie was classified as "Gossip".
I would attribute the inaccuracy in the prediction of the subjects' datasets more to the general vagueness of the rating criterion—"interestingness" than to a failing of the classifier. Given that even the subjects commented on the difficulty of classifying an article as simply “interesting” or "uninteresting", it is not surprising that the subject classfiers failed to completely capture a subject's reading preferences. The low variance of the data also suggests that a larger training set would substantially improve performance, which would be easier to obtain if a person was using the application regularly in a real-world environment.
The success of the specific criterion classifiers suggest that SVMs would be more effective in a content-tagging system for RSS feeds, where a user tags entries based on specific types of content, and the application trains a SVM for each tag to predict whether a story should be assigned to that category. In this way, the user would have a more specific idea of what they are classifying for, which would create narrower categories and hopefully more meaningful results.