Collected data
Using the iPhone, we have taken 547 photographs of the 0th and 1st floors of Sudikoff. The photos are taken at different orientations (portrait/landscape) and are taken at regular, dense intervals throughout the hallways of the building. They are taken at a variety of angles (mostly variation in yaw only, although pitch does change on stairways), although the camera rarely faces the wall directly. The images are from different days, but roughly the same time of day, with similar weather outside.


We are currently in the process of acquiring floor plans (it's harder to find than you might think!) of all three floors of Sudikoff, and are working on a small GUI to match each of our photographs to the appropriate location (and yaw, for orientation) on the floor plan, as a labeling step.
We found an existing implementation of GP
We are currently using the GPML MATLAB scripts from the gaussianprocess.org website to perform regression using GP. Although we did originally say we were going to implement the technique ourselves, we decided to focus more on getting the overall idea working before getting our hands dirty with the details. We have however both read a fair amount on GP and understand them.
We found an existing implementation of the GIST feature extractor
Not much to say about this one.
We ran some simple tests on the collected data using GP
Due to the lack of labeling of the data, we walked the same path from one end of the first floor to the other, twice, taking pictures both times (at more or less random, but dense, intervals). We considered the first walk as a training set and then ran the GP on the second walk. As the images were in the same order both times, a positive result is a monotonically increasing function, which we observed for all but a central segment of the test data.
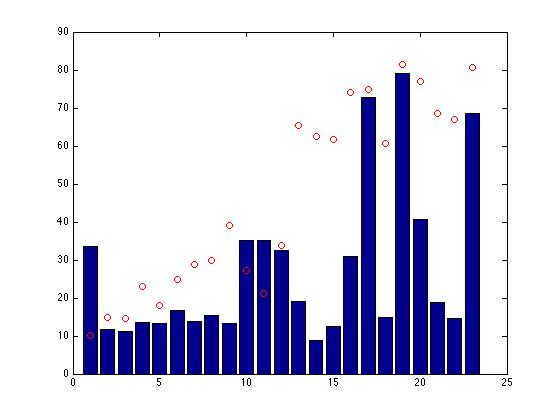
We started examining orientation detection
Given the success of our initial GP tests on plain position, we started looking more specifically at determining not only where the camera is, but what direction it facing. Our current approach is to apply a Hough transform to Canny edges of the L component of the original image converted to LAB* color. This results in many candidate lines that can be grouped into "vanishing points" (there should be three of them), which we intend to feed into a GP (but have not yet done so, due to the lack of orientation labels so far) as features that we believe will be quite strong indicators of camera orientation. We expect this rather naive approach to vanishing point detection to work due to the angular nature of the Sudikoff interior.