Region-based Image Classification
CS 134 Project Mile Stone
Group Member : Qi Gu
Image segmentation is implemented.
Input: image data (type: .jpg)
Output: sequence of regions, each region is represented by 6 features
including color and texture.
Approach:
The image segmentation procedure is based on color
and texture features using a clustering algorithm.
Low level
feature selection:
To segment an image, the system first partitions the image into non-overlapping
blocks of size 4*4 pixels. A feature vector is then extracted for each
block. The size of block is chosen by considering the trade-off between
accuracy and computation complexity. Each feature vector consists of six
features. First three of them are the average L, U and V values of the
pixels in the block. Here the color space we use is LUV, where L encodes
luminance and U and V encode color information (chrominance). The color
space transformation, from RGB to LUV, contributes to a perceptually reasonable
segmentation result. The color space conversion is first done by converting
from RGB to XYZ space, then from XYZ to LUV.
The matching function from RGB to XYZ is below, based on CIE standards
[1]

The transformation from XYZ to LUV is as below:
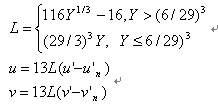
The quantities un' and vn' are the (u', v') chromaticity coordinates of a "specified white object,"[2]
The other three represent square root of energy in the high-frequency bands of the wavelet transforms [3], that is, the square root of the second order moment of wavelet coefficients in high-frequency bands. Applying wavelet transform can average the image information and arrives at a new matrix representing the same image in a more concise manner. It eliminates some unnecessary information. We use Haar wavelet transform on the L component. Haar wavelets are used as they are computationally efficient and have good performance[4].
After a one-level wavelet transform, a 4*4 block is decomposed
into four frequency bands: the LL, LH, HL, and HH bands. Each band contains
2*2 coefficients. Without loss of generality, we suppose the coefficients
in the HL band are
![]()
One feature is
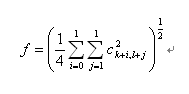
The other two features LH and HH are computed similarly to HL band.
The complete feature vector of a block is in the form of ![]()
Feature vectors clustering:
I use k-means algorithm (I may try other clustering algorithms to do the
comparison in the future) to cluster the feature vectors into several
classes with every class corresponding to one ˇ°regionˇ± in the segmented
image.
K-means clustering is a method of cluster analysis which aims to partition
n observations into k clusters in which each observation belongs to the
cluster with the nearest mean [5]. In other words, k-means tries to find
assignment labels ![]() and
cluster centroids
and
cluster centroids ![]() , minimizing
the following objective:
, minimizing
the following objective:
![]()
The selection of K is important to image segmentation. It determines the
number of regions an image will be partitioned. In the following part,
I will show the different clustering result in terms of K
Experiment and Result:
I setup a scenario to test the segmentation result
in terms of different K
| Ori | K = 16 | K = 8 | K = 4 | |
| African People |  |
 |
 |
 |
| Beach |  |
 |
 |
 |
| Building |  |
 |
 |
 |
| Flower |  |
 |
 |
 |
Figure 1 shows the result of image being segmented into 16, 8 and 4 regions. The result follows our expectation. The similar parts have been merged into the same region and the different parts are separated from each other. Each region is represented by the average color of the area.
Clearly, the resolution of the image decreases as
the K getting smaller. For some complicated images, such as "African
people", when K is quite small, it is quite hard to distinguish main
regions,the same happens to "beach", when K = 16, the shore
and sea are distinctly seperated, but when K = 4, the right part of the
sea shows the same color with shore and makes the region information ambiguous.
On the other hand, for some simple images, such as flowers, even when
K = 4, it is still clear to see the layout of the image.
This comparison implies two possibilities. One is that the segmentation
approach still holds room for improvement, such as in the case of "beach",
even when K = 4 we should still be able to partition the whole image into
sky, ocean, shore and people. The other one is that images from different
categories may require different number of regions to hold the layout
information.
Future Work:
1 Try other clustering algorithm, like Gaussians
2 Implement image representation approach
3 Set up experiment scenario to do the classification test.
4 Analyze and reason the result.
Reference:
[1] Fairman H.S., Brill M.H., Hemmendinger H. (February
1997). "How the CIE 1931 Color-Matching Functions Were Derived from
the Wright¨CGuild Data". Color Research and Application 22 (1): 11¨C23.
[2] Mark D Fairchild, Color Appearance Models. Reading, MA: Addison-Wesley,
1998
[3] D. A. Forsyth and J. Ponce. Computer Vision: A Modern Approach. Prentice
Hall, 2002.
[4] Natsev, A., Rastogi, R., & Shim, K. (2004). WALRUS: A Similarity
Retrieval Algorithm for Image Databases IEEE Transactions on Knowledge
and Data Engineering, 16(3), 301-316.
[5] http://en.wikipedia.org/wiki/K-means_clustering