Information Classification
CS 34/134 Project Milestone
Mu Lin, Shaohan Hu
May 12, 2009
Progress Summary
We have finished most of the coding work: We implemented the majority of the classifiers we
intend to use in the project. Also we carried out our experiments on the 20 Newsgroup dataset as
well as on the small spam/ham dataset included in homework 2. The results are shown in the
following section.
Progress detail
Classifiers
We have by now implemented the following classifiers:
- Naïve Bayes: Our Naïve Bayes classifier is not restricted to binary cases; it
automatically detects the number of classes from the input data, and proceeds with
training and testing.
- KNN: We experimented with different values of K on the 20 Newsgroup dataset.
According to the results we got so far, K = 5 seems to be one of the better choices
for the dataset.
- SVM: We use the one-versus-one strategy to implement the multi-class SVM. Namely
for K labels, we train
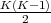 different binary SVMs (one for each pair of classes) and
predict the class that has the highest number of votes. For each binary SVM, we use
Matlab’s svmtrain and svmclassify functions. We are currently working on porting
our own implementation of SVM.
different binary SVMs (one for each pair of classes) and
predict the class that has the highest number of votes. For each binary SVM, we use
Matlab’s svmtrain and svmclassify functions. We are currently working on porting
our own implementation of SVM.
Combination Strategy
We have so far implemented three classifier combination approaches:
- Random selection: We train every single classifier on the training data. Then for each
test document, we randomly select a classifier to label it.
- Majority Vote: We train every single classifier on the training data. Then for each test
document, we assign its label according to the majority vote from all the classifiers.
- Highest Confidence Vote: We train every single classifier on the training data. Then for
each test document, we assign its label according to the classifier that demonstrates
the highest confidence. The confidence is the certainty that each classifier has for its
label inferring. Confidence from different classifiers is normalized into the same range
in order to be comparable to each other. We are working on exploring more sensible
ways for confidence normalization.
Experiments results
The 20 Newsgroup dataset is quite large containing about 20,000 examples and more than 60,000
features, it takes a long time to finish all the training and test for all classifiers and combination
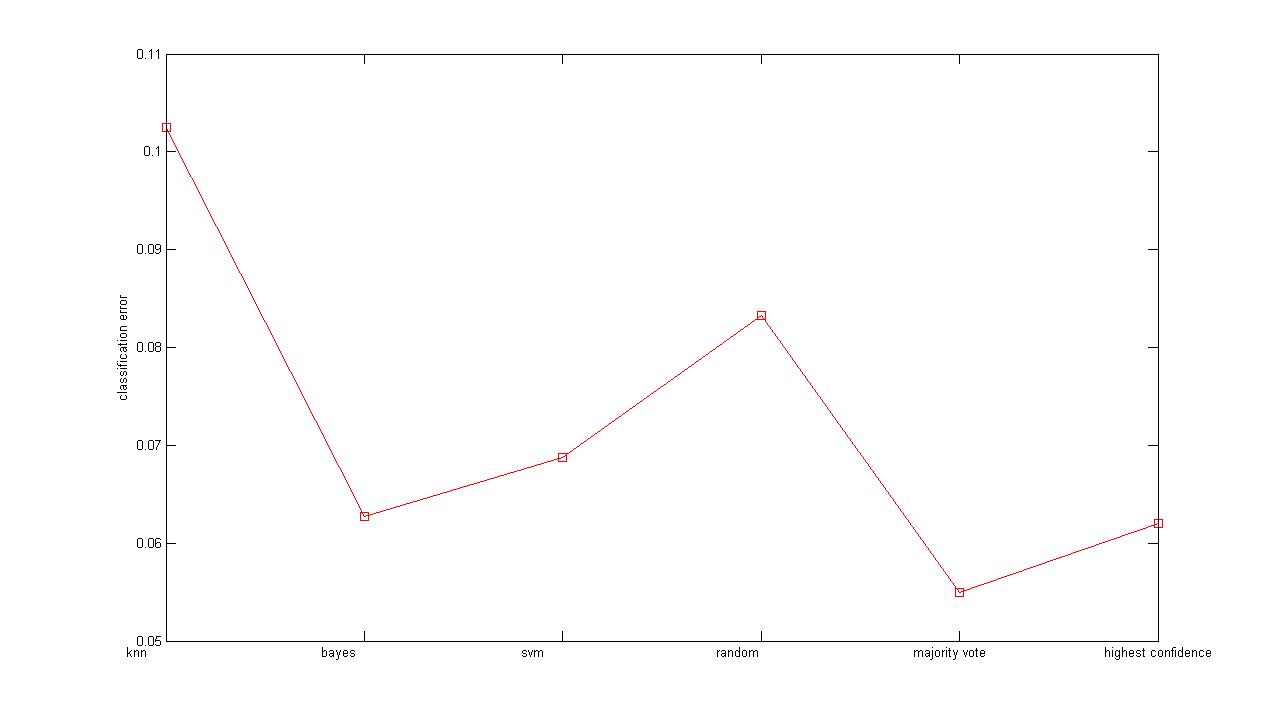
strategies. So at first we did experiments on the a1spam data set included in homework
2, Figure 1 is the plot figure of different classifiers and combination strategies’ test
errors:
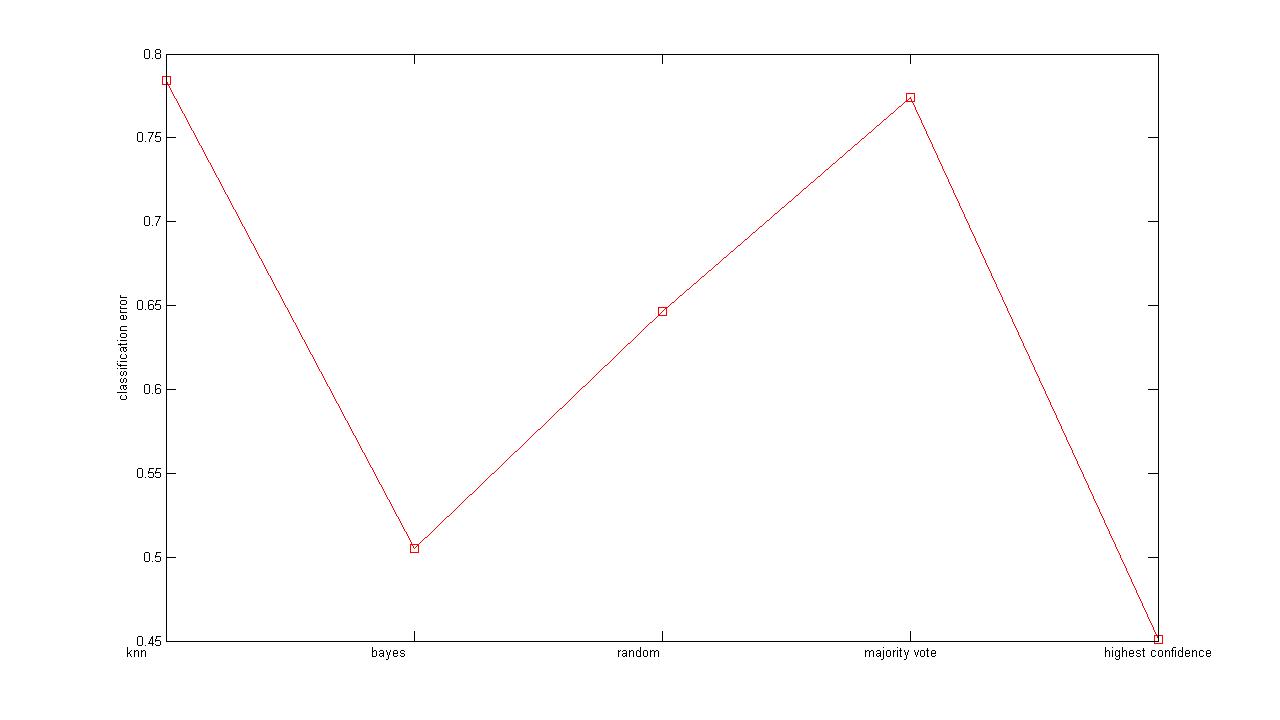
Figure 2 below is the error plot obtained from the experiments on the 20 Newsgroup dataset.
As can be seen from Figure 2, results from the SVM classifier is missing; that is because of
the large size of the 20NewsGroup data—the SVM experiment is still running as of writing, which
actually gives rise to one of the TO-DOs that we describe in next section. What’s also worth
noting from the results is that highest confidence voting actually does perform better over all
other approaches, which is nice to see.
Next Step
- Implementing the Dynamic Classifier Selection approach to combine the different
classifiers together.
- Because the number of features of the 20 Newsgroup dataset is quite large (61188 to be
exact), it currently takes quite long to do training and test on it, and it is more likely
that Matlab runs into memory problems when training the data. So we are thinking
about trying some dimensionality reduction methods to reduce the dimension of the
feature space.
- Finishing up the remaining intended experiments; Analyzing and discussing the
results of experiments. Finishing the final write-up and poster.