Our goal is to predict the performance of a major league player based on the past performance of "similar" players. In our proposal, we planned to predict a small subset of batting data (batting average, home runs, runs batted in) by using a k-nearest neighbor algorithm to determine the identity of the k most similar players to our predictee, then use the neighbors' data to make our prediction.
We laid out two goals for the project milestone:
- Obtain our data, and process it into a database for easy access.
- Implement our machine-learning algorithm in our code.
Our Data
Our main source of data comes from the spreadsheets provided by The Baseball Guru[4], containing batting data spanning from 1997 to 2009. When we found the provided data to be incomplete, Baseball-Reference.com[1] was used to fill in the cracks.
Putting the data together in a database took much longer than anticipated, due to the inconsistency and poor setup of the spreadsheets themselves. While the spreadsheets all contained the relevant statistical data, some of the important metadata (years, ages, unique IDs) was not always included. (For example, the 2004 data did not include ages, the 2003 data lacked ages and IDs, and the 2005 data had neither the ages or a column for the year.) In addition, the unique IDs provided appeared to have been pulled from the Baseball-Reference site[1] and could not always be determined from the spreadsheet alone. To work around these issues, we did the following:
- Ensured that every spreadsheet had a column indicating the year associated with the record.
-
Filled in many of the holes in the age data by building off of the given data (for example, if Player X was n years old in 2006, he was n - 1 in 2005, n - 2 in 2004, etc.) Since 2006 was the earliest year that we had age data for, we used this year as the base for our age calculations. For cases in which no prior age data resided in the spreadsheets, Baseball-Reference[1] was consulted for the missing data, which was propagated from that point on. This manual process had to be repeated for each year, to capture the players who retired before 2006. Some players required multiple manual queries, as injury or poor performance might keep a player out of the major leagues for a year or more and break our algorithm.
NOTE: After calculating the non-existent age data, we recently discovered some issues with the age data provided to us: It appears that the timing of the age snapshot was not the same for the 2006 and 2007 datasets, and as such, some players are listed as two years older in 2007 than they were in 2006. Since we have found that Baseball-Reference[1] appears to agree with the 2006 age listings, and we have built all of our non-existent ages off of the 2006 dataset, we will most likely have to recalculate newer ages using the 2006 data as a baseline. This task, however, remains incomplete.
-
Constructed the new unique ID for each player in the database by concatenating the player's last name with their first name. In the case of name clashes, a middle initial or suffix is added to differentiate between two players. However, this process introduced further problems, as some players appeared in the spreadsheets under several different names. Problems included (among other things):
- Periods after initials (ex. JD Closser vs. J.D. Closser)
- Shortened names (ex. Russell Branyan vs. Russ Branyan)
- Nicknames (ex. Wiklenman Gonzalez vs. Wiki Gonzalez)
- Suffix issues (ex. Jose Cruz vs. Jose Cruz Jr vs. Jose Cruz Jr.)
We also encountered issues with full names being placed together (separated only by a comma) in a single column in some spreadsheets, and in the case of our 2000 data, the first names were left out entirely, save for the first initial. The former issue was quickly resolved by splitting the name cells on the comma, while the latter was fixed by matching the names there with the list of names in the 1999 data and using Baseball-Reference[1] to fill in any names not on the older list.
Fortunately, in the process of manually cleaning up our name data, we verified the data being changed with Baseball-Reference[1] and found the statistical data within the spreadsheets to be mostly accurate. Some isolated examples of inconsistencies were discovered (some players had empty entries in years they did not play in, and in one or two instances a statistic line was attributed to the wrong player), but these errors were few and far between.
Finally, we were able to take our cleaned up data and store in into a MySQL database to make it easier to access and work with for making our predictions. We declared the data spanning from 1997-2008 to be our training set, and held out the 2009 data as a test set for our predictions.
Once the data had been transferred into MySQL, we set a threshold for our data to eliminate outliers-in this case, players with limited batting data such as pitchers or players who saw limited action during their careers. Our threshold was set as follows:
To be considered for our algorithm, a player must have averaged at least 100 at-bats per year for every year of their career.
This threshold may be low (according to our 2009 batting data spreadsheet, the average number of at bats per player was 143.4679931 that year), but still removed a fair number of limited-data outliers while allowing for players to be included despite having a few limited-data years due to injuries or other factors.
Our Algorithm: K-Nearest Neighbor
As stated in our proposal, we used a k-nearest neighbor algorithm to determine the players most similar to the one whose performance we are predicting. Normally, k-NN is used as a classification algorithm, where an object is assigned a label based on the majority label of the nearest k data points[3]. Our approach differs from this idea slightly, as our labels are drawn from either the set of positive integers (for home runs(HR) and runs batted in(RBI)), or the set of positive real numbers (for batting average(BA)). Our algorithm works in the following way:
- Retrieve player x's year-by-year statistics up to the prediction point.
- For every player y in the training set, calculate the year-by-year "difference" between the statistic vectors of x and y up to the prediction point. Note that we compare players via their ages rather than calendar years-for example, we compare what players did at age 25 rather than what they did in 2004.
- Average the yearly differences between x and each y. The k nearest neighbors are the players with the smallest average difference from x.
- Average the k neighbors' statistics at the prediction point to get the prediction for player x.
If we were to take the year-by-year difference between x and every other player y for every year in x's career, x's nearest neighbors would be the players with the k smallest average differences from x.
Results
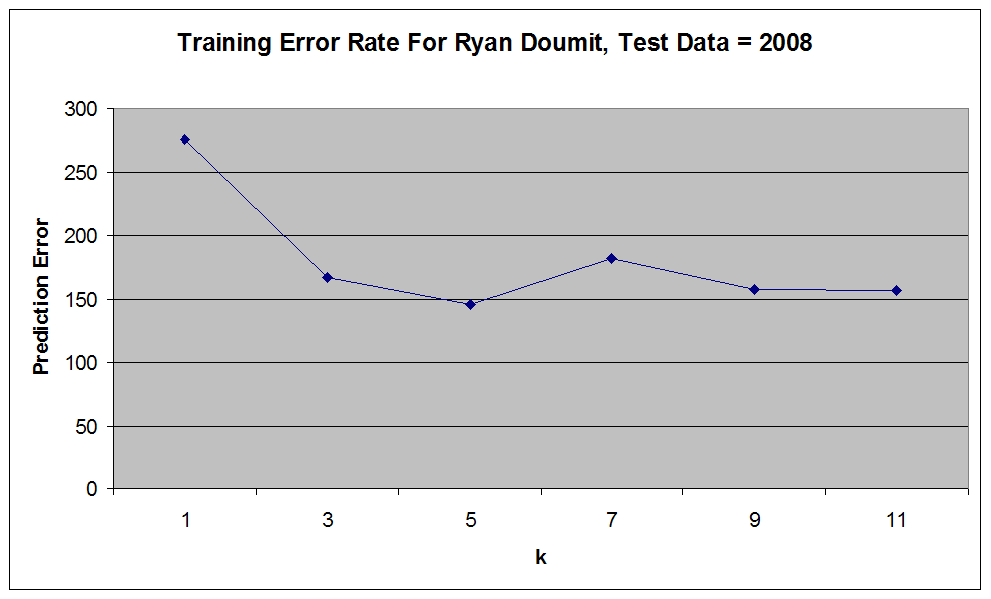
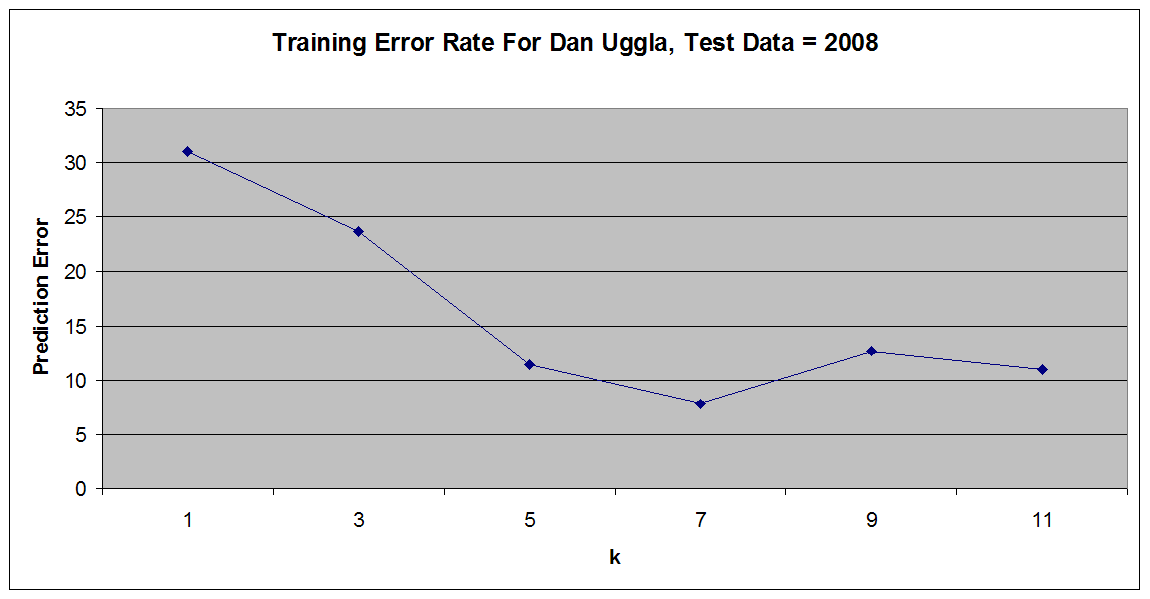
We currently have a k-nearest neighbor algorithm written in Java, which will take a single player within our data set, find that player's k nearest neighbors (excluding the player himself), then make a prediction of that player's future performance based on the performance of the nearest neighbors. Currently, we have set aside our 2008 data as our test set within the training data, and our predictor is hard-coded to predict a player's performance for this year. We are, however, able to run our code using a range of values of k, and compare our predictions with a player's actual 2008 statistics to determine our error values. Below are some example graphs plotting the change in the error rate for certain players as k increases:

(Image From Yahoo Sports[5]) Ryan Doumit (C-PIT) 2008 Statistic Predictions
|
|

(Image From Yahoo Sports[5]) Dan Uggla (2B-FLA) 2008 Statistic Predictions
|
|
(Note that because of the unresolved age issues mentioned earlier, these predictions may change as data corrections are made.)
Next Steps
For the remainder of the project, we plan to do the following:
- Finish cleaning up our age data (and our code, to a small extent).
- Implement a cross validation scheme to allow us to pick the best value of k for our predictions.
- Potentially look more closely at parameter weighting, to see if altering these weights could reduce our prediction errors. This will be done either by hand tuning the weights, or potentially by using some sort of metric learning technique[2] to minimize our error.
- Run our program against our 2009 test set, and report the error rates encountered.
- Complete a write-up and poster for the project.
1. Baseball-Reference.com. Sports Reference LLC, 2000. Web. 12 April 2010. http://www.baseball-reference.com/.
2. Goldberger, Jacob, et al. "Neighbourhood Components Analysis." Conference on Neural Information Processing Systems. 5-10 Dec. 2005, Vancouver, Canada. Cambridge, MA: MIT Press, 2006. Web. CiteSeerX. 12 May 2010. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.79.6605&rep=rep1&type=pdf.
3. "K-nearest neighbor algorithm." Wikipedia.com . Wikipedia, n.d. Web. 12 April 2010. http://en.wikipedia.org/wiki/K-nearest_neighbor_algorithm.
4. "The Baseball Guru's Private Data Archive." BaseballGuru.com. The Baseball Guru, n.d. Web. 12 April 2010. http://baseballguru.com/bbdata1.html.
5. Yahoo! Sports. Yahoo!, n.d. Web. http://sports.yahoo.com/.