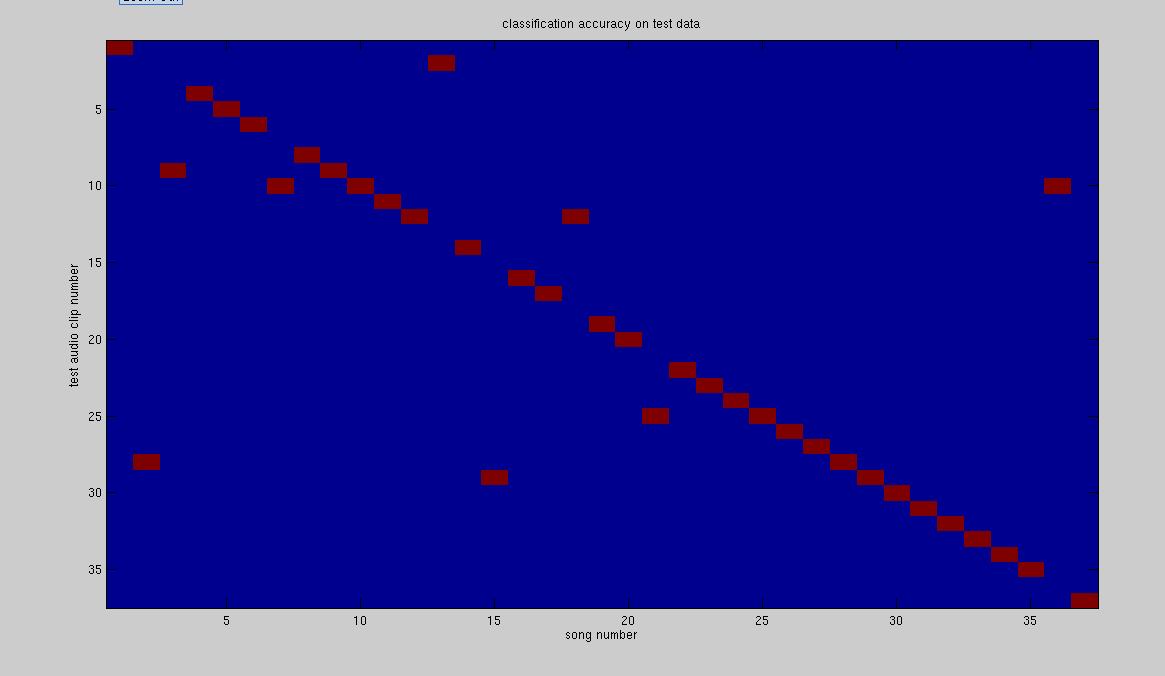
Figure 2: Classification accuracy on test data
These days, the most effective way to search for music is by either using the song name to query a large database of music, or using any of the metadata keywords embedded in the music file to narrow a search on a music database until only a single match is found. What happens though if we do not have any information about the song name or metadata about the song we are looking for? This situation happens more often than one might realize. When watching a television commercial or show, one might hear a very catchy tune, a tune to a song that they have perhaps long forgotten, and they might then be interested in finding the song that the tune belongs to. One technique that humans use effortlessly, but for which few computer applications have been built, is searching for music using another piece of music. When looking for a song, humans can go through all the songs in their playlist, listening to each, and judging whether the currently playing song is the song they are looking for. In this project we explore this idea, and we ask: given a short audio fragment extracted from a piece of music, can we retrieve the full-length song (or its equivalent) that the audio fragment came from?
In answering the above question, we came up with an HMM model to represent songs, with each song uniquely identified by an HMM. Our goal was to have such an HMM trained for all the songs in our database, and have preliminary prediction results by the milestone due date. We have achieved all of the above goals, but through the course of the implementation, we had to introduce some changes. Since we used an HMM toolkit BNT (Bayes net toolbox) to train our song HMM's, we will no longer implement the Baum-Welch algorithm, as we had initially planned to, but will instead implement an alternative prediction algorithm based on GMM's. Details will follow.
Before talking about what is left in the project, let us first talk about what has been accomplished. Our data was drawn from our own music database. It consists of 37 songs of various genres (see table 1), with each song having 3-4mins of audio and an average of 40MB per song of data. Thus our database has approximately 129.5mins of audio and 1.4GB of data. It is not a sizable database, but we believe it is large enough as to be representative of the general performance of the algorithm.
| Genre | Number of Songs |
|---|---|
| Classical | 4 |
| Dance | 4 |
| Hip-Hop | 6 |
| House | 2 |
| Kwaito | 1 |
| New Age | 2 |
| Pop | 2 |
| Punk | 1 |
| R&B | 2 |
| Rap | 1 |
| Reggae | 4 |
| Rock | 6 |
| Soul | 2 |
As in speech analysis, we chose MFCC coefficients as our feature vectors. Alternative feature vectors we could have used include pitch, amplitude, tone, and timbre. Ultimately we went with MFCC coefficients because they were easy to compute, did not warrant any segmentation of the data, and have proved to be at least as effective as other audio signal feature vectors[2]. To compute the MFCC feature vectors, we first had to preprocess our songs, which were largely in mp3 format into wav format. From there we computed an MFCC vector for each 25msec frame of audio data, with an overlap of 10msec between frames. These values are typically used in speech analysis, and a lot of MIR (Music Information Retrieval) papers use them as defaults[1]. Dividing the audio data in this manner leads to an average of 20852 MFCC feature vectors. Since each MFCC feature vector is composed of 13 components, for each song we have a 13x20852 matrix of data, of which we assign 50% to the training set and the other 50% to the test set.
Our algorithm for retrieving a song based on a sample audio clip is thus:
The results are tabulated in table 2 below.
| Data | Correctly Classified | Percentage |
|---|---|---|
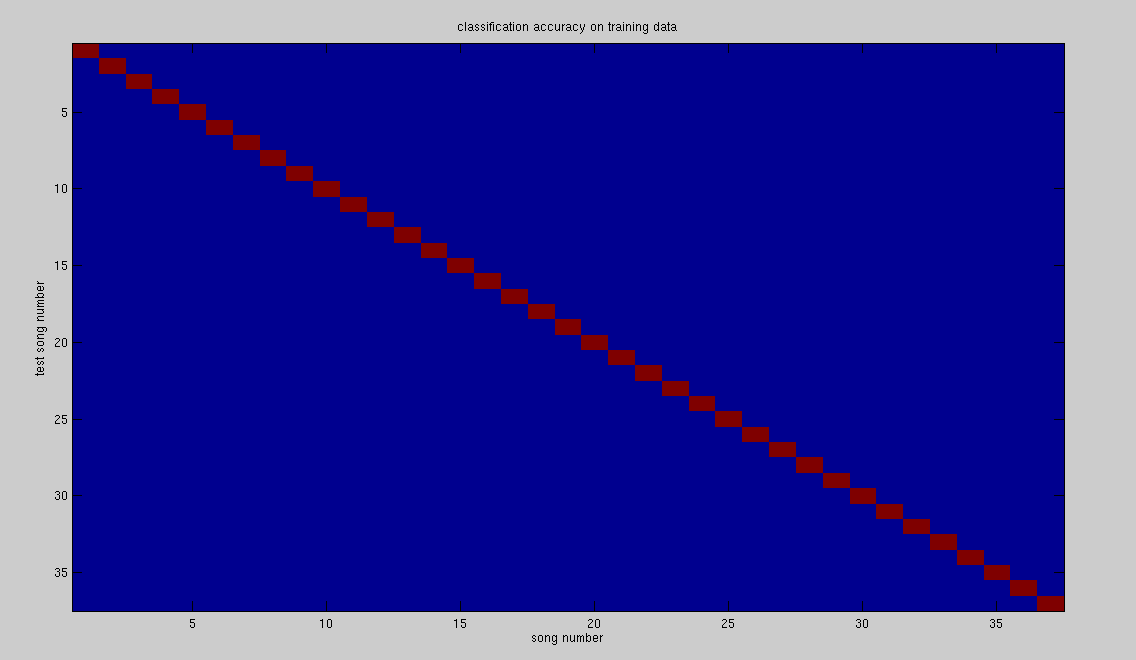
| train set | 37 | 100% |
| test set | 29 | 78.4% |
The above results were computed over the whole data base, with the HMM training taking 40mins and the evaluation taking another 40mins. Figures 1,2 below are plots of table 2, showing the pattern of misclassification.
The above results are promising in terms of using HMM's as audio search engines. The results can be improved, as previous work with HMM's[1] could reach accuracies of up to 98%. The paper cited did however use full length segments as queries, and did not consider audio clips shorter than the song length. The HMM approach is also quite expensive in terms of computation time; for the 37 song data base a single query takes about 40mins/37 = 1.1mins. This evaluation time can be decreased by keeping the songs in memory during testing (the above query includes I/O time), and by using other optimization techniques. Our work for the remaining weeks then is to drive the evaluation time (we do not care much for the model building as this can be done offline), and to determine the most appropriate topology of HMM that gives the best results. Lastly, since most of the results were obtained with the help of an HMM toolkit, we will be using a Gaussian Mixture Model based algorithm to match audio clips to songs, and will compare the results to the HMM based approach.