

Next: Schedule
Up: Increasing the I.Q. of
Previous: Approach
Datasets
We'll use the 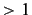 GB of email from our gmail account to train and
test our model. First, we'll parse the email corpus to collect
subjects, recipient sets, and message text. Then we'll remove
punctuation within the text and split the corpus 90/10,
GB of email from our gmail account to train and
test our model. First, we'll parse the email corpus to collect
subjects, recipient sets, and message text. Then we'll remove
punctuation within the text and split the corpus 90/10, 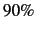 for
training our model and
for
training our model and 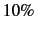 for testing. Finally, we'll compute
for testing. Finally, we'll compute
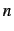 -grams over the training set using
-grams over the training set using  and use these
-grams
to compute next-word likelihood within our model.
and use these
-grams
to compute next-word likelihood within our model.
jac
2010-04-13