Figure 1: Architecture of the text
summarization system
Feature Identification
The
following features have been used by various researchers in the past
to determine whether a phrase or a sentence should be included in
the final summary:
- Position
of a sentence
- Frequency
of each word
- Semantic
importance of each word
Few
researches have investigated in measuring semantic importance of
each word to determine the importance of each sentence. However it
remains a question whether the semantic features are efficient
indicators of how important a sentence is. During this project, the
semantic features will be extracted from a graphical representation
of each document. A Document Graph (DG) [7] is a directed acyclic
graph that captures the semantic relationships between noun/noun
phrases. Within a DG, there are two types of nodes: concept
nodes and relation nodes. A concept node contains a noun or a noun
phrase and a relation node links two concept nodes. Two types of
relations are defined – the “isa” relation and the “related to”
relation. A Prepositional phrase-heuristic (PP-heuristic), a Noun
Phrase heuristic (NP-heuristic), and a Sentence heuristic
(S-heuristic) are used to extract relationships from a sentence for
inclusion in a DG. The NP-heuristic mainly defines set-subset
relationships between two concept nodes and is denoted using the
“isa” relation. This heuristic also generates “related to”
relationships between the main noun phrase and the supporting terms
in that noun phrase. An example of a DG
built from sentence "Military members support nuclear weapons." is
shown in Figure 2.
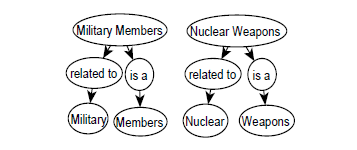
Figure
2: An example of a document graph
Milestone Deliverables
By the milestone date, I want to finish all the three stages
(pre-processing, training as well as the evaluating stage)
illustrated in Figure 1. After the milestone, more analysis will be
conducted such as comparing the performance of different
classification methods, comparing the performance of various
training sample size and so forth. The detailed timeline is listed
as the following:
~ April 19th: Finish the pre-processing stage: Measure
features of each word
~ April 26th: Finish the training stage: Implement
various classification algorithms and train the models using n-fold
cross validation
~ May 3rd: Finish the evaluating stage
~ May 11st: Prepare presentation slides
References
[1]. Wikipedia, "Summary - Wikipedia, the free encyclopedia,"
2010. [Online]. Available:
http://en.wikipedia.org/wiki/Summary
[2]. C. Y. Lin and E. Hovy, "Identifying topics by
position," in Proceedings of the fifth conference on Applied natural
language processing. Association for Computational
Linguistics, 1997, pp. 283-290.
[3]. H. P. Edmundson and R. E. Wyllys, "Automatic
abstracting and indexing—survey and recommendations," Communications
of the ACM, vol. 4, no. 5, pp. 226-234, 1961.
[4]. G. Erkan and D. R. Radev, "Lexrank: Graph-based
lexical centrality as salience in text summarization," Journal of
Artificial Intelligence Research, vol. 22, no. 1, pp. 457-479,
2004.
[5]. C. M. Bishop and Others, Pattern recognition and
machine learning. Springer New York:, 2006.
[6]. J. R. Quinlan, C4. 5: programs for machine learning.
Morgan Kaufmann, 1993.
[7]. Nguyen, H. (2005). Capturing User Intent for
Information. Ph.D. Dissertation, University of Connecticut.
[8]. The official website of Document Understanding Conference
(DUC).
http://duc.nist.gov/

_text_