Smart Stock Selection
Final Report
Chanjuan Wen
May 31, 2011
1 Introduction
- Public stock data is limited. The key to accurate analysis of stocks’ performance is the availability of high quality financial data. For individual stock traders, high quality financial data is usually too expensive to get. For example, we can only get the daily open price, close price, and trading volume of a stock.
- Influencing factors are too many to consider. The performance of a stock can be influenced by a lot of factors, such as the company’s coming event, revenue, stock traders’ activities, etc. Besides, each stock has many properties, including the company’s total asset, annual revenue, etc. The underlying relations between those factors, properties, and performane is very hard to figure out.
Since long term invesetment(months or years) requres fundamental analysis of the company’s performance and financial record, and super short-term (1-2 days) investment will be only available to large financial coorperation due to the high commission fee and need high quality financial data, in this project, I mainly focus on short-term stock trading (1-2 weeks).
So, the goal of this project is to help investors make short-term stock investment by constructing a profitable stock portfolio using machine learning techniques. A portfolio is a set of stocks the investor will hold in a prerid of time. An investor is able to gain money by buying stocks in low price and selling them in higher price. To maximize the profit of a profolio, investors need to select stocks with a high return rate. Let Vi denote the initial value of an investment, and Vf denote the final value of it, then the return rate is[6]:
2 Previous Work
- Predict the price trend of individual stocks. In this category, classification algorithms such as SVM are used to predict whether the price of some stock will go up or down in certain future time. However, this type of prediction is not that useful because it does not reflect the amount of change. For example, a stock with 0.01% increase in price and one with 100% increase in price will both be predicted as going up. Obviously, a stock with 0.01% increase is not as profitable as the one with 100% increase.
- Predict the exact price of individual stocks. Pham et al[7] used deep correlation algorithm to predict the next day’s price of individual stocks based on today’s information of stock trading. This type of prediction mainly focus on minimizing the overall average prediction error, which is not suitable for my task, since the goal here is to identify high return rate stocks. The prediction errors of low return stocks and negtive return stocks are not important.
- Predict the exact stock index. Related work, such Theodore and Huseyin[8], includes using SVM for the whole stock forecasting, i.e., pridicting the exact stock index. For individual stock traders, the exact stock index is not useful for stock selection because the increase of the whole stock market’s index does not neccessarily mean the increase of individual stocks. Moreover, the stocks we want to choose have to outperform the stock index. Otherwise, we can just buy the stock index.
3 Objective
4 Approach
4.1 Competitive Learning Based Non-parametric Model
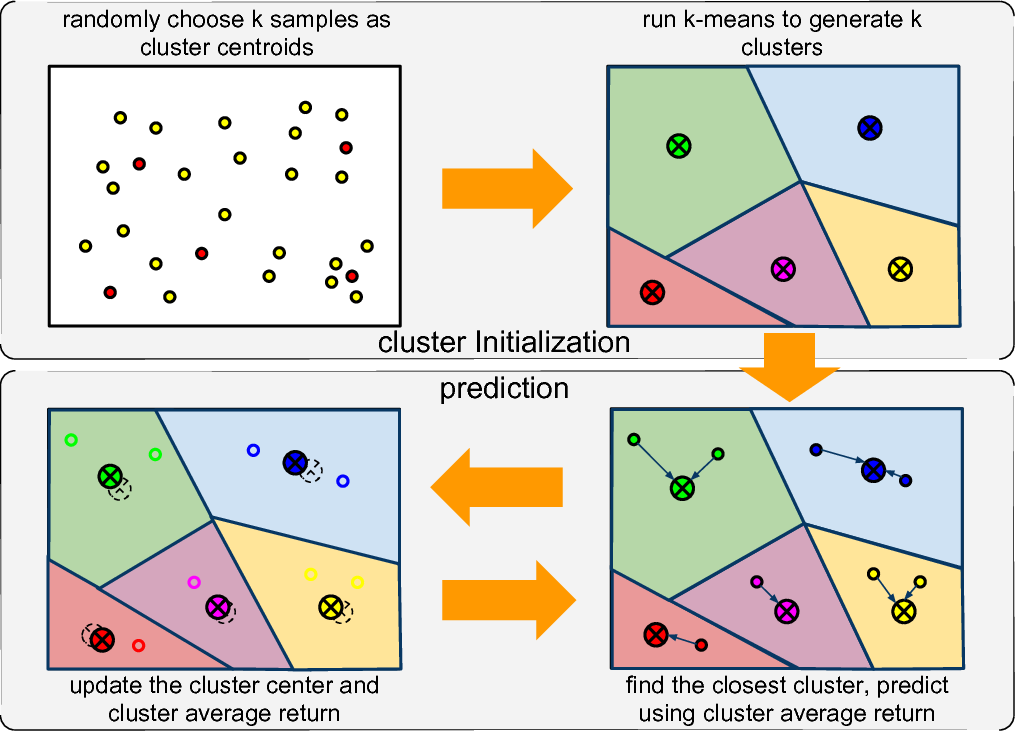
- Cluster Initialization. Firstly, in the 3-D feature sample space, I randomly choose k samples as the cluster centers. Then in the K-means method, firstly, for each feature sample, I calculate its distance to every cluster center and choose the closest cluster to label it. Then by fixing the cluster label of each feature sample, I update the cluster center by averaging all the feature vector belonging to that cluster. By repeat this process until convergence, I can get k cluster. Meanwhile, for each cluster center, the average feature vector and weekly return are also recorded. After getting the k clusters, I use the feature vectors of the k cluster centers to construct a Kd-Tree for nearest neighbor search in the prediction stage.
- Return Prediction. For each stock i in week t denoted by x(i)t, I use Kd-Tree to find its nearest cluster c, and use c’s average return as the predicted return for x(i)t. After predicting the weekly return for all stocks, I choose N stocks with the highest return to form the portfolio.
-
Cluster Update. At the end of week t, we have the actual return of all stocks for week t. So, we can update the clusters. There are two things needed to update as follows:
- Update the cluster centers. For each stock i, I use its feature vector to update the center of cluster which i belongs to. Let xjavg denote the average feature vector of cluster j, n denote the number of feature samples belonging to j, then the update equation is: xjavg = (xjavg*n + x(i)t)/(n + 1).
- Update the average return of each cluster. For each stock i, I use i’s actual return at week t to update the average return of cluster which i belongs to. Let rjavg denote the average return of cluster j, n denote the number of feature samples belonging to j, then the update equation is: rjavg = (rjavg*n + r(i)t)/(n + 1).
4.2 Other Models for Comparison
4.2.1 Linear Regression
Here, the θi’s are the parameters parameterizing the space of linear functions mapping from X to Y[11]. Given a training set, we choose θi’s which can minimize the sum of squared differences error denoted as follows:
4.2.2 Nonlinear Regression
Similar to Linear Regression, we choose θi’s which minimize the sum of squared differences errors. Since some nonlinear functions may cause overfitting while some other may cause underfitting, choosing a good nonlinear function is very important.
5 Experiment
5.1 Data Retrieving
5.2 Data Preprocessing
So, after preprocessing, my dataset includes 500 weeks data of 462 stocks.
5.3 Feature Selection
-
Competitive learning based non-parametric Model. As stated in Cooper’s work[13], to predict the return of week t, I choose the actual return of week t − 2 and t − 1, and the volume value ratio, denoted by VR(t) to compose the feature vector. The volume value ratio and feature vector for my method is:
x(i)t = [R(i)(t − 2), R(i)(t − 1), (V(i)(t − 1) − V(i)(t − 2))/(V(i)(t − 2))] -
Linear Regression. In this method, I simply merge the actual return and trading volume of the previous two weeks. Since the trading volume is usually more the order of 106 which is much more than the price, to avoid numerical precision issues in computation, I transform the trading volume values using a scaling factor which we set to be 106. Let α denote the scaline factor, then the feature vector for the Linear Regression model is
x(i)t = [1, R(i)(t − 2), V(i)(t − 2) ⁄ α, R(i)(t − 1), V(i)(t − 1) ⁄ α] -
Nonlinear Regression. Similar to the Linear Regression, for this method, I choose the actual return and trading volume of the previous two weeks. The difference is that I use a quadratic function to generate the feature vector for the Nonlinear Regression model.
x(i)t = [1, x1, ⋯, x4, x21, x1x2, ⋯, x1x4, x22, x2x3, ⋯, x2x4, ⋯, x24] x1 = R(i)(t − 2) x2 = V(i)(t − 2) ⁄ α x3 = R(i)(t − 1) x4 = V(i)(t − 1) ⁄ α
5.4 Parameter Configuration
6 Results
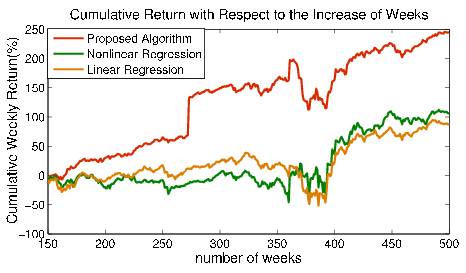
7 Conclusion
References
[1] http://en.wikipedia.org/wiki/Stock
[2] http://en.wikipedia.org/wiki/Stock_market_prediction
[3] Robert J. Y, John N., Charles X. L. Application of Machine Learning to Short-term Equity Return Prediction. 2006.
[4] Avramov D., Chordia T. Predicting stock returns, Journal of Financial Economics 82, 387-415. 2006.
[5] Hamid S.A., Iqbal Z. Using neural networks for forecasting volatility of S&P 500 Index futures prices, Journal of Business Research 57, 1116-1125. 2004.
[6] http://en.wikipedia.org/wiki/Rate_of_return
[7] Hung P., Andrew C., Youngwhan L. A Framework for Stock Prediction. 2009
[8] Theodore B. T., Huseyin I. Support vector machine for regression and applications to financial forecasting. IJCNN2000, 348-353.
[9] Robert J.Y, Charies X.L. Machine Learning for Stock Selection. The 13th ACM SIGKDD international conference on knowledge discovery and data mining. New York, USA, 2007: 1038-1042
[10] http://en.wikipedia.org/wiki/Linear_regression
[11] http://www.stanford.edu/class/cs229/notes
[12] http://en.wikipedia.org/wiki/Nonlinear_regression
[13] Cooper M. Filter ruies based on price and volume in individual security overreaction. Review of Financial Studies, 1999(2): 901-935