Speech Emotion Recognition
Qingyuan Kong

Speech Emotion Recognition
Qingyuan Kong
Goal:
I want to make the computer automatically recognize the emotion in the speech, such like fear, angry, happiness. The recognition is based only on voice, without knowing the contents of the speech.
Methods:
The algorithm contains following steps:
Extract the components of each speech:
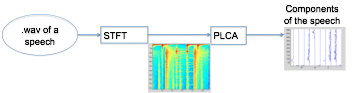
PLCA is a source separation algorithm used to extract repeating components.
PLCA model:
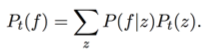
Pt(f): each frame of the STFT result at a given time t is considered as a distribution along the frequency domain;
z represents a component, so Pt(z) is the possibility of a component z at time t.
P(f|z): each component is considered as a distribution along the frequency domain.
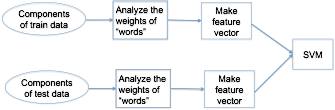
Extract the components of each emotion:

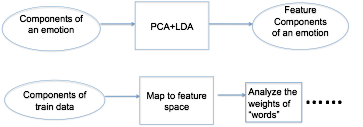
Here we use the concept of “bag of words”: consider each component of an emotion as a “word”, use all the “words” to construct a “dictionary”. Use the weights of all the “words” in a speech to construct a feature vector to represent the speech, and then train a multi-class SVM to do the classification.
The updating model used to calculate the weights of “words” in a component of a speech:
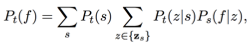
Pt(f): a component of a speech;
s represents an emotion;
Ps(f|z): the component z of emotion s;
Pt(s): the weight of emotion s;
Pt(z|s): the weight of the component z, a “word”, of emotion s;
Pt(s) and Pt(z|s) are learnt through updating.
Note: in our model, each component of a speech can be represented as a vector of weights of “words”.
To construct the feature vector, we have two choices: one is to use the mean of all vectors of all components, one is to use the mean and the covariance matrix, which is changed to a vector.
Variants of the system:
There are several variants for the system.
Variant 1: Before input to SVM, apply PCA+LDA to the feature vector. PCA+LDA can reduce the dimension of the feature vector and map it to a feature space where the points may be better clustered.

Variant 2: apply PCA+LDA to the components of emotions, map them to a feature space, and then map the training and test data to the same space.
Variant 3: use Mfcc feature to extract components of the speech. Since Mfcc feature works well on this task, so we use Mfcc feature instead of results of STFT to extract components. But this method does not work.
Dataset:
The dataset we used to examine our algorithm is “a database of German emotional speech”, which contains 800 sentences (7 emotions * 10 actors * 10 sentences + some second versions). The link for the dataset is http://database.syntheticspeech.de/
Results:
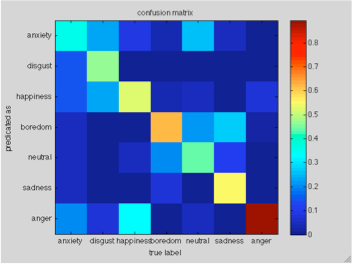
confusion matrix
The x label is the true label, and y label is what predicted as. Each grid is the ratio of data from label x and predicted as label y.
Accurate rate for each emotion
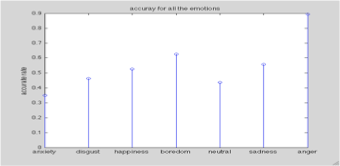
The figures above are from variant 1 of the system, with “mean of all components” as feature vector.
Results of different models:
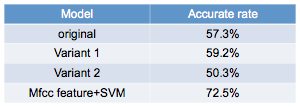
Discussion:
The results above are best results for each model among all the choices of feature vectors and parameters. We compared our algorithm with mfcc feature, which is commonly used in speech recognition systems. However, our algorithm cannot defeat mfcc feature.
The drawbacks of our algorithms are:
1 the “words” we select are not discriminative enough. Because we use plca to find repeating patterns in an emotion as “words”, we are not guaranteed that the “words” from different emotions will be different enough.
2 our model is based on finding repeating patterns in a speech. But the key information for separating different emotions may be in how the patterns change with time. Though we try to use covariance matrix to capture the changing of patterns, it may be not capable of capture the information.
3 After we found mfcc feature works better, we tried to use mfcc feature instead of the result of STFT to extract components, it still works badly. So we will try to use different methods to process mfcc feature in future.
Reference:
1 Paris Smaragdis, Bhiksha Raj, “Shift-Invariant Probabilistic Latent Component Analysis”, TR2007-009, December 2007
2 MVS Shashanka, Latent Variable Framework for Modeling and Separating Single Channel Acoustic Sources, Department of Cognitive and Neural Systems, Boston University, August 2007