Project Milestone Report
Car detection on mobile phones
Tianyu Wang
Introduction
Cell phone users exhibited a higher percentage of unsafe behaviour than normal pedestrians. In studies from Ohio State University, the authors examined distraction of pedestrians associated with mobile phone use. [1] Pedestrians speaking on the phone, and walking across the street may not be able to see the approaching cars from their phone side. It may lead pedestrians into sever traffic accidents or injuries. So I propose a mobile application that captures the street view by the back camera of the phone and detects cars font view in the images in real time. If there is a coming car approaching to the mobile phone user the application will alert user immediately.
Related work and algorithms
Because of the special features of the car, such as head lights, tires and dark bottom line, I propose to use Adaboost Learning algorithm to perform the car detection.
Challenges
The great challenge in the project is that the images captured by the mobile phones may not be well aligned. The cars in the image can be of any orientation. To obtain a good accuracy, the images fed to the adaboost classifier need to be aligned by the gravity orientation. Another challenge is that it is hard to collect the large variety of cars by myself on the mobile phone. In this case I will merge two car front view database and adjust the quality of these training images according to my experimental phone, Nexus One.
Preprocess training images
1. Training datasets:
MIT CBCL CAR DATABASE #1: 516 128x128 PPM format images (http://cbcl.mit.edu/software-datasets/CarData.html)


Caltech Cars 2001 (Rear): 526 images of rear view cars (http://www.vision.caltech.edu/html-files/archive.html)


Negative images: Google Street View images with no car 250x150 large images
.jpg)
Preprocess:
1. Crop the car regions and form 40x40 grayscale images. Remain as little background as possible in the positive samples to get better results.
2. Equalize color histogram in the whole image.
3. Contrast deviation.
4. x and y axises distortion.
We formed a training dataset as the figure below:

AdaBoost algorithm
In WalkSafe application we used Gentle AdaBoost Learning algorithm,
which is implemented by OpenCV library, to train a cascade of boosted classifiers working with
haar-like features. Gentle AdaBoost Learning algorithm is known to be the most robust AdaBoost
variation version at present. Detail of the Gentle AdaBoost Learning algorithm is described in
related work section. The first three haar-like features that selected by the Gentle AdaBoost
Learning algorithm are as Figure 4. In the training phase, the positive images are resized as 20x20 pixels.
By resizing the image to a smaller pattern, we expect to reduce the affect of different image quality using
different cameras for training images and test images. We trained the cascade classifier by 20 stages.
In each stage, a weak classifier is trained, in which 0.999 hit rate and 0.5 false alarm rate are preserved.
More specifically we used a single layer of decision tree as the weak classifier in each stage.
Two kinds of decision trees are used as the weak classifier. One is the stump decision tree with only one split node,
and the other is CART tree with two split nodes. The accuracy of the two cascade classifiers are evaluated
in the evaluation section. The following figure is the four most presentive features that we extracted from GAB algorithm.

Car detection model evaluation
To evaluate the performance of the car detection models, we selected 48 cropped car front view and rear view images and 300 Google Street View images different from the training dataset, and generated 216 testing images with car location annotated in the images. Two Haar-like cascade car detection models are trained by Gentle AdaBoost algorithm as what we described in the previous section. One car detection model is trained using a simple tree stump in each weak classifier, and the other is trained using CART decision tree with two splits in each weak classifier. We trained the Haar-like cascade car detection model using 20x20 positive pattern size. 0.999 hit rate and 0.5 false alarm rate are set in each weak classifier training phase. We applied the two car detection models on the same test dataset. The ROC curves of the two models are shown in the following figure.
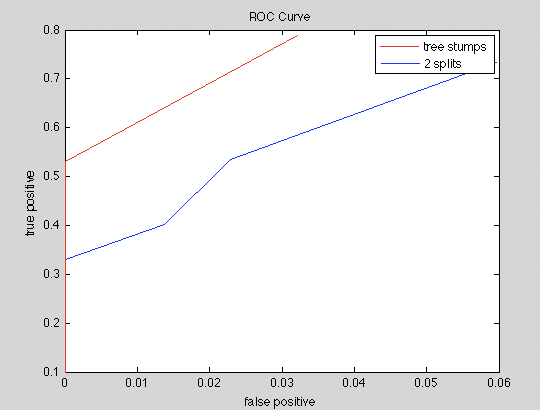
The reason that simple tree stumps classifiers have better performance than 2 splits CART, might be due to the overfitting problem in the training dataset. More experiments should be done for each weak classifier to proof this hypothesis in the future.
Mobile phone detection
In the end we implemented the car detection model on the mobile phone. More experimental results and application design will be pulished soon in my future work.
In the folloing figure we present some snap shots of the car detection model on Nexus One

References
- Jack Nasar et al, "Mobile telephones, distracted attention, and pedestrian safety", Accident Analysis and Prevention 40 (2008) 69-75
- MIT cbcl Car Database, http://cbcl.mit.edu/software-datasets/CarData.html
- The PASCAL object recognition database collection. http://www.pascal-network.org/challenges/VOC/
- Lee, D. “Boosted Classifier for Car Detection.” Carnegie Mellon University.
- Caltech Rear View Car 2001 dataset http://www.vision.caltech.edu/html-files/archive.html
- Tutorial: OpenCV haartraining (Rapid Object Detection With A Cascade of Boosted Classifiers Based on Haar-like Features) http://note.sonots.com/SciSoftware/haartraining.html