Robust Visual Servoing
Scott Teuscher – CS134 Spring 2011
Problem Statement
Our current micro unmanned vehicle system utilizes a custom built open loop servoing system to track regions of interest within an image. We use the tracking mechanism to capture high quality still images for computing structure from motion. We have also developed a custom closed looped inertial stabilized gimbal camera system. The open loop system was eventually chosen due to simplicity of the control structure. The purpose of this project is to utilize reinforcement learning to diminish the necessity for hand crafting the nonlinear closed loop controller and eliminate the need for an expensive inertial sensor while meeting or exceeding the capabilities of the open loop system.

Figure 1 - Closed Loop Gimbaled Camera
Methods & Results
I am implementing the Neural Fitted Q algorithm as stated in the project proposal.

I have chosen the states to be position of the region of interest in the image and gimbal angles. I am using a discretized action space which is broken into five values for each motor, this leads 25 possible combinations of actions. The instantaneous reward function is as seen below in equation 1.
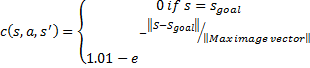
The reward function
takes only the image space into account as I do not want to reward or penalize
for gimbal angles. It also allows a
small reward closer to the center of the image.
I have implemented the automatic state transition data collection methods, i.e. blob tracking as well as encoder value capture, necessary to train the Q function neural network. I am taking advantage of the Neural Network Tool box to train and estimate the Q function. I have currently run the system on a simple 4-1 MLP network and have not consistently seen convergence to the goal of keeping the region of interest in the middle of the image. An example of the Q values for the 4-1 MLP from 10 episodes with up to 20 sample iterations and a learning rate of 0.05, a greedy implementation, can be seen below.
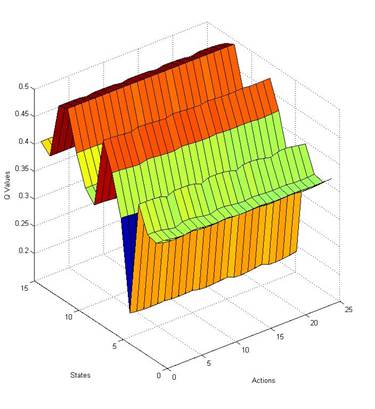
The states are the time progression of the system. It can be explained as at state 1 the action corresponding to the minimum Q value was chosen resulting in state 2. It can be seen that we reached very close to the goal and achieve very low Q values for the state 4, but the system executes a random action every 4 iteration and thus never converged on the goal state.
Risks and Future Work
One of my main concerns is the correct selection of the neural network. To solve this I will first explore previously implemented neural network structures in a very greedy non exploratory implementation to test for convergence of the system to the goal state. This will be evaluated by the number of episodes for 100% tracking. If unsuccessful I can also implement other regression techniques such as linear regression for the Q function estimation. I am also going to investigate dedicated hardware for the blog tracking to decrease the time for each episode, as I am running the vision code in matlab.
Schedule
April 21 – Automated data collection system fully operational. - Complete
May 10 – Minimal Fitting of selected algorithms - Compete
May 24 – Selection of best controller - Complete
References
[2] M Reidmiller: “Neural fitted Q iteration-first experiences with a data efficient neural reinforcement learning method”, Machine Learning: ECML 2005, 2005 – Springer.