Style-based image retrieval and
inference of stylistic classes
James M. Hughes
COSC 134 - Machine Learning and Statistical Data Analysis
Spring 2011
Problem Statement
The availability of large collections of digital images via the Internet has necessitated the development of algorithms for searching for and retrieving relevant images, given a particular query [1,2,6]. Traditionally, these algorithms have described images in terms of associated metadata (such as tags), as well as with content-based features and statistical descriptions [3,4,5]. Furthermore, while the digitization of vast archives of cultural artifacts has made these objects more accessible both to the general public and to researchers, the increase in their availability requires more efficient means of locating objects relevant to a particular query [6,7]. Critically, when we consider new classes of images, it may no longer be the case that these images are best described by features related to their content. In the case of works of art, one obvious means of describing these objects is by statistical features derived from their digitized versions. These features could then be used to facilitate a style-based image retrieval system that returns stylistically relevant images with respect to a query image (or query string). I propose a system that implements similarity-based image search using a query image provided by the user, along with the ability to automatically learn the stylistic categories that describe style relationships between images from feedback on search results provided by the system.
Methods
My proposed model is a combination of probabalistic inference of stylistic categories and a system to recommend images to users, based on a query image I and a set of stylistic categories, each of which has an associated weighting of stylistic features. I will address the methods for dealing with each aspect of the project individually.
Image features
The stylistic image features themselves are based on (relatively) recent work in the field of computational stylometry [8,9,10,11,12,13,14]. Methods from applied statistics, signal processing, and physics have been used to understand the quantitative characteristics of works of art that account for our perception of style [15,16]. This project will attempt to combine these features in order to learn stylistic distinctions that go beyond simple questions of attribution or authenticity, which are the areas that, up to this point, have received most of the attention in the field of computational stylometry. Nevertheless, I will describe art images according to a number of features that have been shown to discriminate between artistic styles [9,11,12,13,15,16].
Recommendation model
Given a query image I, a similarity-based search system should return images that are "relevant" to the input. For this, one must have some notion of what is a relevant image, and relevance could be based on statistical features, associated metadata, or other features [3,4,5,17,18]. The notion of relevance that I will use in this model is described in more detail below. However, assuming we have some notion of relevance, we need to provide the user with images T from a set of images that are likely to be relevant to the query image.
This suggests a model in which the probability of an image being relevant is some function of the similarity between the features associated with the query image I and a possible related image T_i. A natural way to model this relationship is via logistic regression with a linear model [19]:
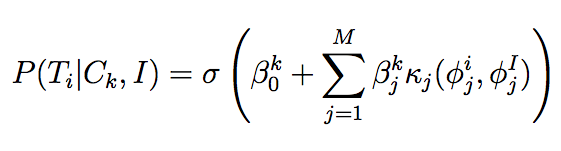
where C_k is the relevant stylistic category (for example, "color"), beta_k is a set of weights associated with C_k, and sigma is the logistic function. The kappa_js are similarity functions between sets of features phi_j that each image possesses (see above). Note that this function is really modeling the probability that image T_i belongs to the same category as image I (i.e., it is a binomial logistic regression model in which the two classes are "in-category with respect to I" and "out-of-category with respect to I," given a class C_k). Other forms of binary classifiers could be used (e.g., probit regression), but it is useful to consider models that provide real-valued probabilities, rather than a "hard" clustering.
Style inference model
In order to know which stylistic category C_k is relevant to the query image, we must infer this from the feedback the system receives from the user. Once a set of images is displayed, the user may choose a subset of them as relevant; this set is taken to represent "in-category" images. Among the set of images displayed, the remaining images (i.e., the ones the user does not indicate are relevant to the query image) are taken to be the "out-of-category" images. Given the entire set of images D_t and their associated target variables (1 for in- and 0 for out-of- category), using the function defined above, we can infer the posterior over stylistic classes:
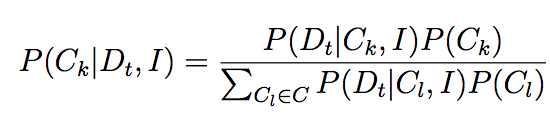
Initially, we assume a uniform prior over stylistic classes C_k. Note also that we assume that C_k does not depend on I. With this model, we can infer the stylistic class the user has chosen to define images relevant to the query image by for example choosing the C_k with the largest posterior probability. Once this choice has been made, we can suggest relevant images according to the model described above.
After a user has selected a set of relevant images and a stylistic class C_k has been chosen, we can update the class's parameter vector beta_k according to the gradient of the negative log-likelihood [19]. For each query, we eventually assume that the user is considering a particular stylistic category when deciding which images are relevant, and in order to incorporate this information with previous information, we perform gradient descent on the current set of relevant and disregarded images (i.e., those not chosen as relevant by the user), using the current estimate of beta_k as the starting point. Once beta_k has converged, we average the two vectors to create the final estimate of beta_k.
Data
I have a large collection of high-resolution art images (on the order of several thousand) that span a number of stylistic categories, including in some cases images of several dozen art works by the same artist, from all of which I will extract a set of stylistic features. I will also crawl Google Images for art images of several stylistic periods in order to obtain labeled exemplars that can be used to validate the model (for example, by training on a subset of the images labeled "post-impressionist" and then determining for a new query image if the set of most probable resultant images belongs to the same labeled category). I anticipate that for testing I will have at least one hundred images per category.
Goals & Timeline
Ultimately, the goals of my project are as follows:
- Implement the similarity-based image search model as described above
- Implement the stylistic inference model as described above
- Validate the model and assess its performance on a set of labeled exemplars
- Gather data on human usage of the model (in an unsupervised fashion) in order to automatically derive stylistic categories
I anticipate that by the first milestone (May 10, 2011), I will have collected a large set of images (both from my own current collection as well as from the Internet) and computed features for these images. I will also have begun implementing the model (probably will have the recommendation model complete and will have begun the style inference model). If I complete some of these objectives ahead of schedule, I will begin testing the model in a supervised fashion (as described above). In the remaining time, I will concentrate on refining the model and analyzing its performance, as well as testing its performance in an unsuperised fashion using human subjects.
References
- "Google image search," http://www.google.com/images.
- "Bing image search," http://www.bing.com/images.
- N. Vasconcelos, "From pixels to semantic spaces: Advances in content-based image retrieval," IEEE Computer, 2007.
- M. S. Lew, N. Sebe, C. Djeraba, and R. Jain, "Content-based multimedia information retrieval: State of the art and challenges," ACM Transactions on Multimedia Computing, Communication, and Applications, 2006.
- Y. Chen, J. Li, and J. Z. Wang, Machine Learning and statistical modeling approaches to image retrieval. Kluwer Academic Publishers, 2004.
- "Google Art Project," http://www.googleartproject.com/.
- S. Hockey, "The history of humanities computing," in A Companion to Digital Humanities, Blackwell Publishing, 2004.
- R. P. Taylor, A. P. Micolich, and D. Jonas, "Fractal analysis of Pollock's drip paintings," Nature, vol. 399, June.
- J. M. Hughes, D. J. Graham, and D. N. Rockmore, "Quantification of artistic style through sparse coding analysis in the drawings of Pieter Bruegel the Elder," Proceedings of the National Academy of Sciences, vol. 107, pp. 1279-1283, 2010.
- R. Taylor, R. Guzman, T. Martin, G. Hall, A. Micolich, D. Jonas, B. Scannell, M. Fairbanks, and C. Marlow, "Authenticating pollock paintings using fractal geometry," Pattern Recognition Letters, vol. 28, pp. 695-702, 2007.
- L. van der Maaten and E. Postma, "Identifying the real van Gogh with brushstroke textons." White paper, Tilburg University, February 2009.
- I. Berezhnoy, E. Postma, and H. van den Herik, "Authentic: computerized brushstroke analysis," pp. 1586-1588, 2005.
- J. C. R. Johnson, E. Hendriks, I. Berezhnoy, E. Brevdo, S. Hughes, I. Daubechies, J. Li, E. Postma, and J. Wang, "Image processing for artist identification," IEEE Signal Processing Magazine, vol. 37, July 2008.
- S. Bucklow, "A stylometric analysis of craquelure," Computers and the Humanities, vol. 31, pp. 503-521, 1998.
- D. Graham, J. Friedenberg, D. Rockmore, and D. Field, "Mapping the similarity space of paintings: image statistics and visual perception," Visual Cognition, 2009.
- D. Graham, J. Friedenberg, D. Rockmore, and D. Field, "Efficient visual system processing of spatial and luminance statistics in representational and non- representational art," vol. 7240, pp. 1N1-1N10, 2009.
- J. Z. Wang, J. Li, and G. Wiederhold, "Simplicity: Semantics-sensitive integrated matching for picture libraries," IEEE Transactions on Pattern Analysis and Machine Intel ligence, vol. 23, no. 9, 2001.
- I. J. Cox, M. L. Miller, T. P. Minka, T. V. Papathomas, and P. N. Yianilos, "The bayesian image retrieval system, pichunter: Theory, implementation, and psychophysical experiments," IEEE Transactions on Image Processing, 2000.
- C. M. Bishop, Pattern Recognition and Machine Learning. Springer, 1st ed., October 2007.