Introduction:
NBA is regarded as one of core constituents of modern professional sports with around $4.1 billion dollars of revenue in the 2010-2011 season [1]. Meanwhile, professional betting, which is another billion dollar industry, heavily depends on the accurate game outcome prediction [2]. The goal of this project is implementing Machine Learning algorithms to predict outcome of a game/series by given two NBA teams' statistics.
Dataset:
The NBA dataset is downloaded from www.databasebasketball.com. The raw data contains the year-long NBA statistics of players, teams and coaches for both regular seasons and playoffs. I only use data of seasons 2008-2009 through 2009-2010 due to the consistency, since whole NBA league kept changing because of old team quitting and new team joining since 2000s.
- Training set: team data and game results of 2008-2009 regular NBA season.
- Test set: team data and game results of 2009-2010 regular NBA season.
In this project, the regular season team stats are used as X. There are 32 features in total including offensive and defensive statistics, pace and wins of that specific season. These 32 features are the difference of the feature between the two compared teams. In total, I have 435*32 matrix as train and test set where 435 are the total series number of one regular season. Intuitively, a team's offensive stats are the stats "earned" from the opponents, while a team's defensive stats are the stats "earned" by the opponents. In addition, I found several dominant features of game accuracy prediction, such as wins for each team, defensive assists, defensive points, defensive field goals made and offensive rebound in previous season.
| Features | wins | d_ast | d_pts | d_fgm | o_reb |
|---|---|---|---|---|---|
| Accuracy | 0.6939 | 0.6293 | 0.6199 | 0.613 | 0.611 |
Y is the series outcome of two teams. For example, Boston Celtics plays two games against Los Angeles Lakers in their series. If Celtics wins two games, the series outcome of Celtics is 1, the opposite is 0. However, if they draw, the series outcome will be determined by the most dominant feature, i.e. wins for each team in previous season. The series outcome will be 1 of the team with higher wins rate. Due to lack of the accumulative season data from the database, it is only possible to use series outcome instead of game outcome as Y. In other words, it is impossible using same X data to predict game results of 1 win and 1 lose. That's a limitation of the dataset which I will talk in the later part.
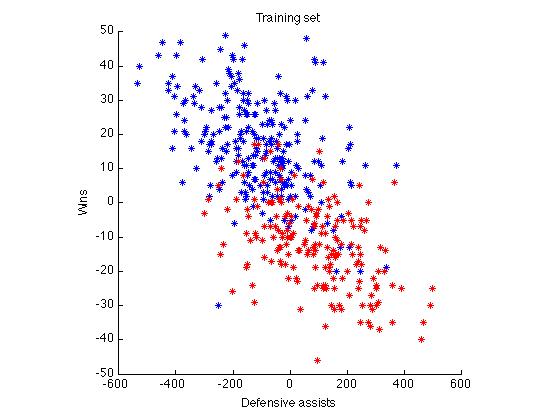
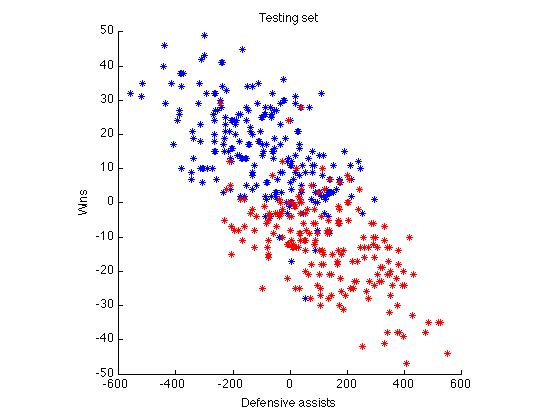
Figure 1. Training and test set of the two most dominent features.
Algorithms:
In order to get a better understanding of the prediction accuracy, I examined several related work of game outcome prediction. Michael et al. [3] reported up to 73% accuracy to predict NBA games when using linear regression. Hamadani [4] used logistic regression to predict NFL games with accuracy of 64.8%. Radha-Krishna [5] predicted soccer matches with accuracy of 65.5% when using neural networks. In this project, I plan to implement 5 machine learning binary classification methods.
-
Linear Regression: it is the very first algorithm introduced in this class. It used least-squares function to estimates the relationship between X and Y. I have 32 features as input to firstly predict the series outcome using the following model:
, where
is the feature weights vector.
-
Logistic Regression: it is a widely used techniques for classification. It differs from linear regression by using a sigmoid function. By using maximum likelihood estimation, the model converged around 450 iterations using an epsilon threshold value of
. The following logistic function is implemented to predict the outcomes:
, where
- KNN: it is a discriminative and non-parameter algorithm which is easy to implement. The idea is to classify the variables by finding k nearest neighbors. During my test, using k = 3 and cosine distance will give me the best result of both series and game outcome prediction.
- AdaBoost: It constructs a strong classifier by a weighted combination of different weak classifiers. The weak classifier is using a single feature to predict outcome based on that feature difference of two teams. On each round, the weights of misclassified examples are increased, while the weights are decreased if classify correctly. In my project, the first round provides the most satisfied prediction results through classifying by most dominant feature, i.e. wins of the previous season.
- Artificial Neural Networks: it is usually used as a classifier based on the concept of biological neural networks. At first I am looking forward to digging out some of the hidden internal information of the input data. By using a existing Matlab Neural Network toolbox, the main structure is a feed-forward back-propagation network. The final architecture is 32 inputs to 1 target and 1 hidden layer with 5 nodes through multiple tests of different hidden layers and numbers of nodes. In the experiment, the learning rate is 0.02 and goal is 0.01. Training method is gradient descent with momentum.
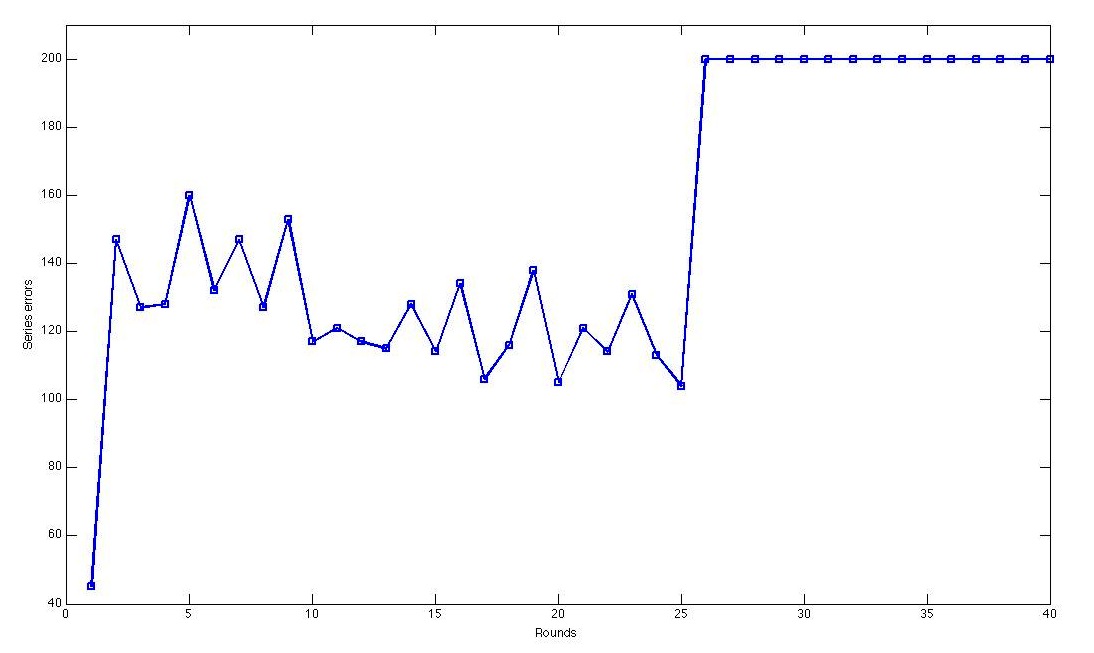
Figure 2. Misclassified examples of first 40 rounds using AdaBoost.
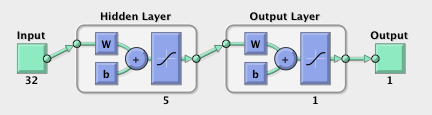
Figure 3. Artificial Neural Networks Architecture.
Results:
I provided the prediction results of the five implemented algorithms. From the table below, all methods achieve a very satisfied series prediction accuracy except linear regression. And all the algorithms except linear regression again keep consistent of test set and 5-fold cross validation which indicate that the results don't depend on specific data set. However, the game prediction accuracy drops a lot due to the collected data limitation. Overall, the AdaBoost seems to be the best classification algorithms in both game and series prediction.
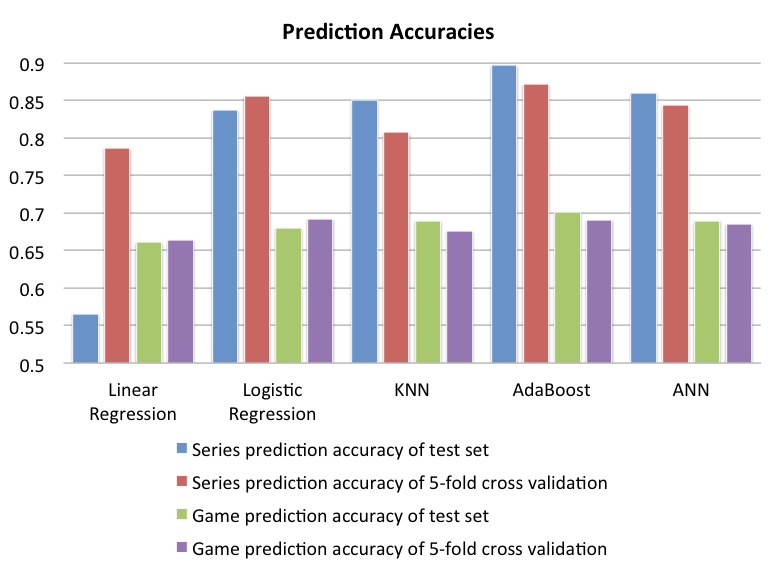
| Algorithms | Linear | Logistic | KNN | AdaBoost | ANN |
|---|---|---|---|---|---|
| Games Prediction Accuracy | 0.661 | 0.6797 | 0.6894 | 0.7016 | 0.6894 |
| Series Prediction Accuracy | 0.5655 | 0.8368 | 0.8506 | 0.8966 | 0.8578 |
| Algorithms | Linear | Logistic | KNN | AdaBoost | ANN |
|---|---|---|---|---|---|
| Games Prediction Accuracy | 0.6642 | 0.6919 | 0.6756 | 0.6902 | 0.6846 |
| Series Prediction Accuracy | 0.7862 | 0.8552 | 0.8069 | 0.8713 | 0.8437 |
Conclusion:
- All the algorithms could provide very satisfied prediction accuracies of outcomes. AdaBoost and Neural Networks are even stronger than three simple approaches.
- Lack accumulative team season stats to predict game outcomes accurately. After long search, I fail to find accumulative season team data so that only predict next season results based on overall stats of the previous season. Meanwhile that's the main reason why game prediction is lower than expected. Nevertheless it is encouraging that four of the five implemented algorithms offer a very satisfied series prediction results.
- Lack long consistent season stats. Currently, I only use two seasons stats as training set and test set respectively. The NBA league is famous of rapid change through new team joining and old team quitting. So it is very hard to find consistent stats for consecutive several years since 2000. Although early 1990s has a long lasting data online, I am afraid its reliability is not as satisfied as recent data. Therefore cross validation is implemented to test more cases.
| Source | Random Guess | NBA experts | Website[9] | Other researchers[3] | Smart NBA prediction |
|---|---|---|---|---|---|
| Accuracy | 50% | 71% | 65% | Up to 73% | Up to 90% and 70% |
Reference:
[1] Sports Industry Overview
[2] McMurray, S. (1995). Basketball's new high-tech guru. U.S. News and World Report, December 11, 1995, pp 79 - 80.
[3] Michael Papamichael, Matthew Beckler and Hongfei Wang, NBA Oracle, 2009.
[4] Babak, Hamadani. Predicting the outcome of NFL games using machine learning. Project Report for CS229, Stanford University.
[5] Balla, Radha-Krishna. Soccer Match Result Prediction using Neural Networks. Project report for CS534.
[6] Alan McCabe, An Artificially Intelligent Sports Tipper, in Proceedings : 15th Australian Joint Conference on Artificial Intelligence, 2002.
[7] Yoav Freund, Robert E. Schapire. "A Decision-Theoretic Generalization of on-Line Learning and an Application to Boosting", 1995.
[8] Paul A. Viola, Michael J. Jones, "Robust Real-Time Face Detection", ICCV 2001, Vol. 2, pp. 747.
[9] ESPN