Our task is to classify 120 breeds of dog appropriately using machine learning methods. For this project, We had tested and observed several classical methods(kNN, SVM). However, these traditional approaches were actually not fitted to classify 120 classes. Thus, we implemented our new approach by combining classifiers and compared to our new approach (Decision Tree with SVM).
- Observing the Dataset
- Our dataset contains 12000 examples with 120 breeds (for 100 examples). We used both kernelized matrix and non-kernelized matrix. The kernelized matrix has been applied histogram intersection kernel. The number of features of the former is 12000, the latter is 5376. The dataset came with annotation, labels and bounding boxes.
- K-NN classifier
- We implemented k-NN classifier for testing. k-NN method easy to implement so we could build several k cases (it is known that its perfermance is fairly good) and compare the accuracy to our main SVM method.
- We implemented k-NN classifier for testing. k-NN method easy to implement so we could build several k cases (it is known that its perfermance is fairly good) and compare the accuracy to our main SVM method.
- Multi-class SVM(one-vs-one)
- Tested multi-class SVM classifier could classify 12 of 120 total dog breeds.
To see more specific result, please click HERE
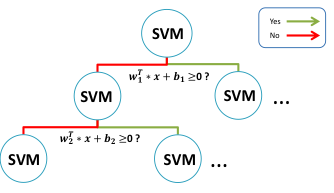
- Randomly assigning binary labels to examples
- Learn a binary split of data using SVM result from the first step and keep 'W' and 'b'. W in here indicates weight vector and b is bias for SVM hyperplain.
- Force examples labeled 1 (y = 1) to right child node. Otherwise, move it to left child
- Organize Random forest by building more trees. Trees must be built independently.
General idea
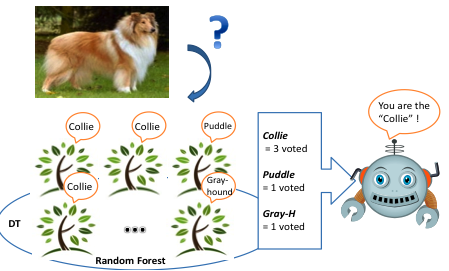
- We introduced combined method to get better accuracy result for our classification problem. We used Decision tree but omitted entropy calculation and picking the most effective feature based on entropy. Instead of using entropy, we applied the process of binary SVM for each tree nodes. we built Random forestwith up to 10 independent trees for each sample. Building trees took a lot of time but the generalization error of a random forest could be reduced by making reducing the correlation among the trees. If trees are once grown up through the training step, the trees vote the correct class for given test set.
Traning step
![]()
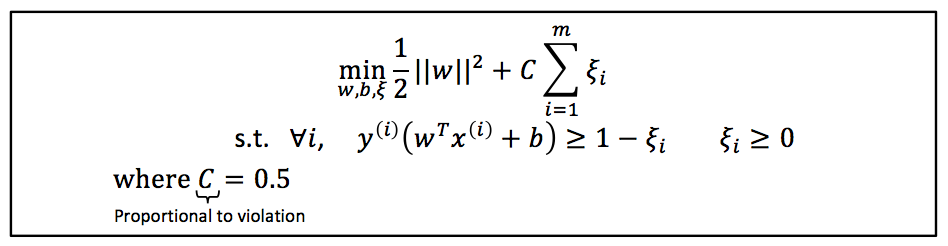
Testing step
- Each tree will classify individually given test data.
- Collect results and vote.
- Assign the labels following the "most" voted class
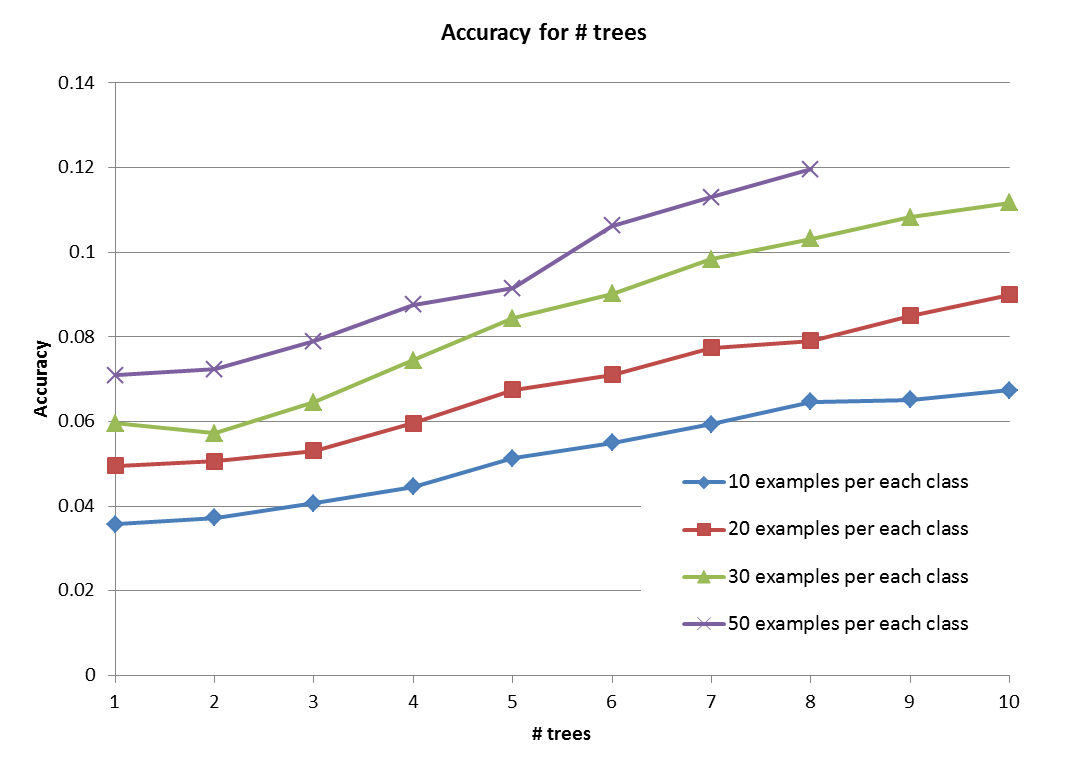
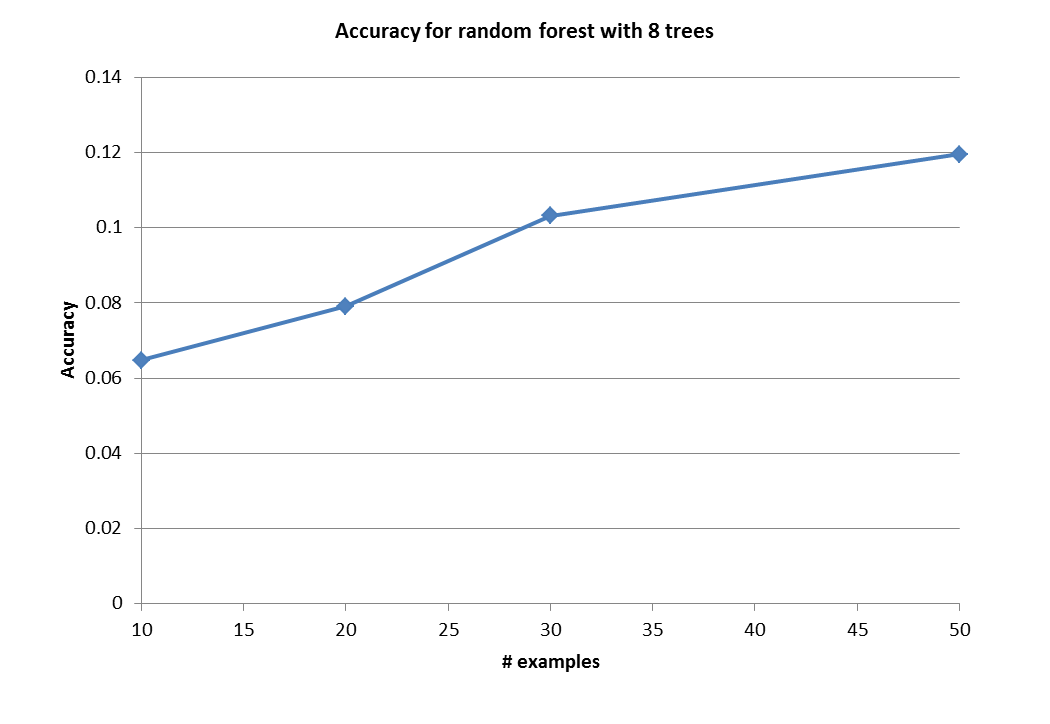
First of all, we need to mention that we did not use entire 100 examples from each class. The reason is because we had system limitation, we could not even run ML methods with that amount of data (Even Dartmouth research computing system could not run this program). Thus, we have run our apprach by choosing part out of entire example set (n = 10, 20, 30, 50 , we could not run if n is larger than 50).
As we can see above the results, we got the better accuracy result by inceasing number of samples from each breed. This is because each tree could learn more accurate 'W' and 'b' on training step. Moreover, we could get better performance result as we increased number of trees that consist of Random forest. Our trees were indepently built (reduced correlation), and they returned better results. Thus, we could get some conclusion "the more trees the better result"
Due to the time limitation, we only could try our approach with only up to 10 trees and 50 examples. However, we expect we can get close result compare to Stanford vison lab's experiment in respect that our graph.
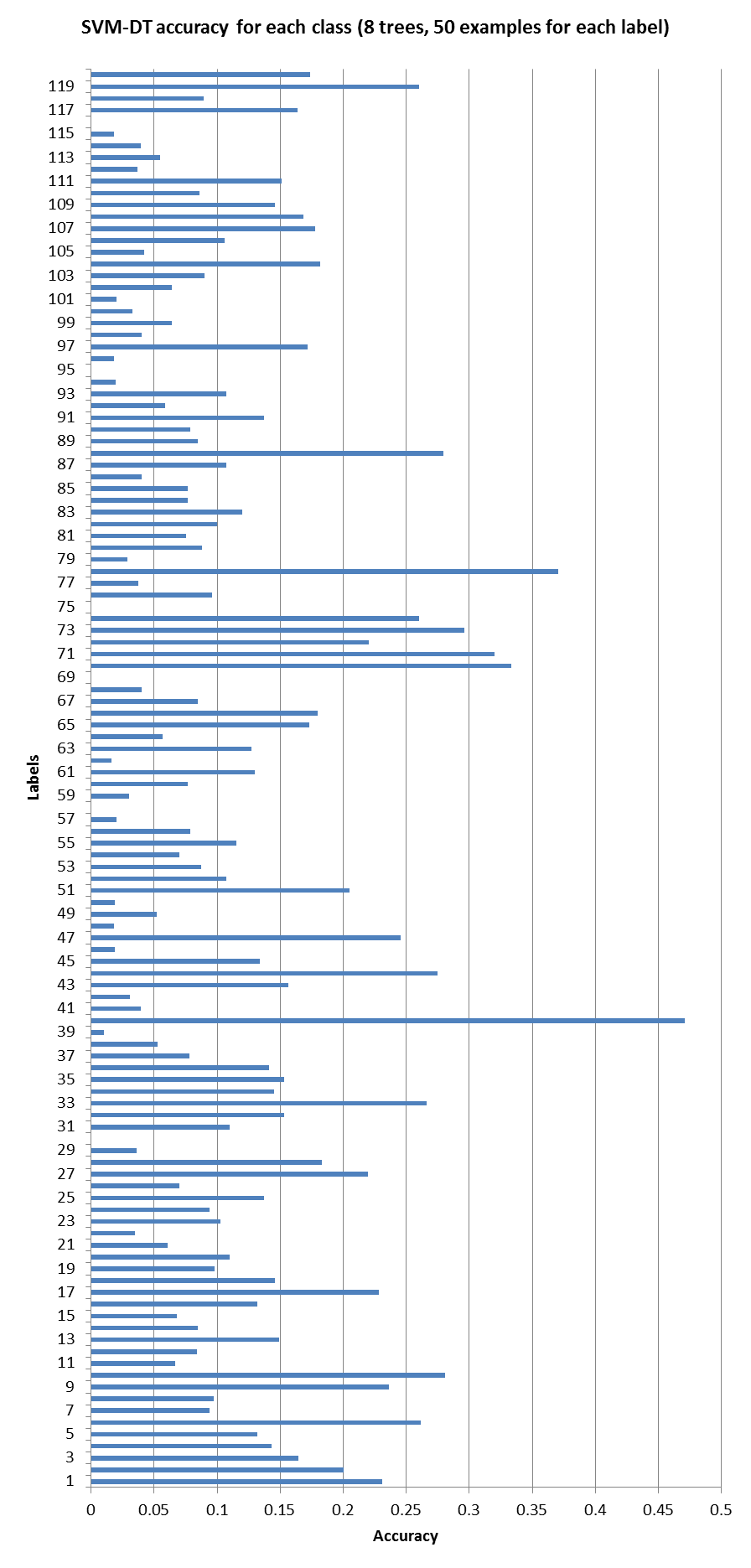
- [1] Stanford Dogs dataset, Stanford Vision Lab
- [2] Aditya Khosla, Nityananda Jayadevaprakash, Bangpeng Yao and Li Fei-Fei. Novel dataset for Fine-Grained Image Categorization. First Workshop on Fine-Grained Visual Categorization (FGVC), IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2011.
- [3] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li and L. Fei-Fei, ImageNet: A Large-Scale Hierarchical Image Database. IEEE Computer Vision and Pattern Recognition (CVPR), 2009