Calculate the covariance coefficients r of the test image and all the sample images. Pick the label that has the largest r.
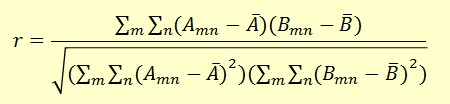
Use 544 images, segmented into 2648 symbol images for testing.
Accuracy: 73.19%
Goal
Reading contextual information embedded in scene images is one of the crucial problems in computer vision. The difficulty lies in that the images are taken in real word circumstances, in which case they could be blurred by noise, light, background etc. The characters may be distorted or overlapped. Furthermore, word fonts vary a lot. So the goal of this project is to use image processing and machine learning algorithms to recognize the words from scene images both efficiently and correctly.
Data
The dataset used in this project is from ICDAR 2003 Robust Reading Competition.
In the training set, there are 598 images of words cut from the original images and a single text file with the ground truth transcription of all images. In the test set, there are 544 images with a ground truth text file.
Method
1. Image preprocessing
2. Word segmentation and normalization
3. Word recognition using unsupervised learning
4. Word classification using KNN method
5. Word classification using Neural Network (backpropagation)
Image Preprocessing
1. Sharpen the image when necessary. For blurred images, sharpening is needed to better detect the edges and find the threshold. The method I used is based on the gradient of the image. After sharpening, the original region with smoothing grayscale doesn't change much, while the ones with steep grayscale become steeper, so as to enhance the image details. Here's an example.
2. Convert RGB image to grayscale by using Matlab function rgb2gray().3. Calculate the threshold using OTSU algorithm and S.Watanabe Algorithm, based on image histogram. For my dataset images, the OTSU method works better.
4. Convert grayscale images to black and white, according to threshold, by setting the pixel one if it is greater than the threshold, and zeros otherwise.
5. Determine the background of the image and change all images to black characters with white background. This is easier for the next segmentation process.
Word Segmentation and Normalization
1. Segment the words based on region connection. Scan the image from left to right, up to down, label the pixel by looking at the four processed neighbors, then resort the labels by inversely scanning the image. For example,
2. Remove the non-character section by eliminating the labeled region that is below the 100 percent of the image area.3. Cut the image into individual characters and normalize each isolated character to 42*24 size.
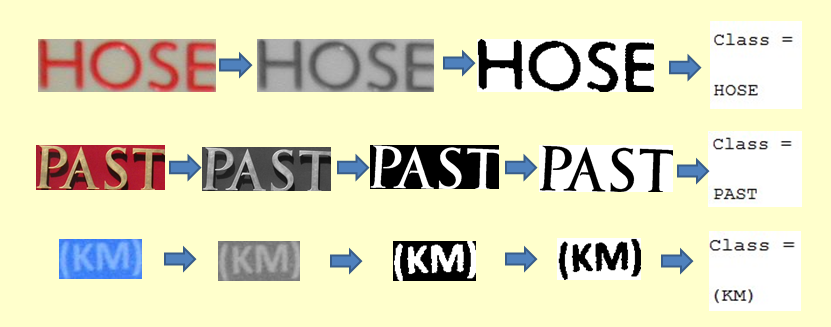
Below are some examples of the process.

Unsupervised Learning
Create 70 sample symbol images.

Calculate the covariance coefficients r of the test image and all the sample images. Pick the label that has the largest r.
Use 544 images, segmented into 2648 symbol images for testing.
Accuracy: 73.19%
Supervised Learning with KNN
Use KNN classifier with cosine distance.
Use 596 images, segmented into 3195 symbol images for training. Use 544 images, segmented into 2648 symbol images for testing.
Accuracy: 92.87%
Below are some examples of the process.
Supervised Learning with Neural Network
1. Resize every binary character image obtained from the segmentation step into a 10 by 10 binary matrix. The main reason for doing this is that the original segmented character images are of size 42 by 24, making the input neurons of size 1008, which is difficult to control when picking the size of hidden layers and hidden neurons. After resizing, a neural network is constructed with 100 input neurons with nonlinear transfer function (tansigmoid). See the binary matrix for "S" below as an example. 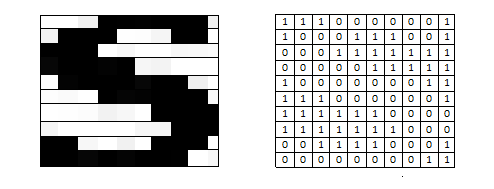
2. Start with 1 hidden layer. Pick 55 as the number of hidden neurons for optimal results. The output layer has 41 neurons, corresponding to 10 numbers (0~9), 26 English alphabet, and 5 symbols "?" "!" "&" "(" ")". The transfer function between the hidden layer and the output layer is non-linear (tansigmoid). The structure of the neural network is shown below. 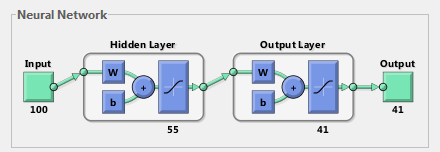
3. The network is trained with gradient descent with momentum backpropagation training function ("traingdm"), with 596 images, segmented into 3195 symbol images. The simulation conditions are set for optimal results. See the parameters as follows.
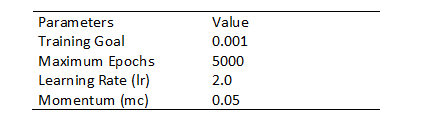
Get training accuracy of 90.02% in about 5 minutes. The process stops after 5000 epochs with mean square error of about 0.003. The details are as follows. 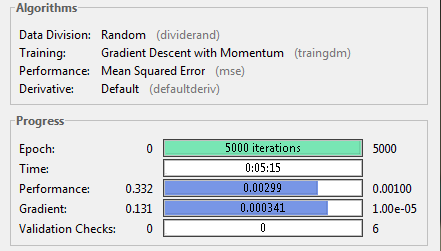
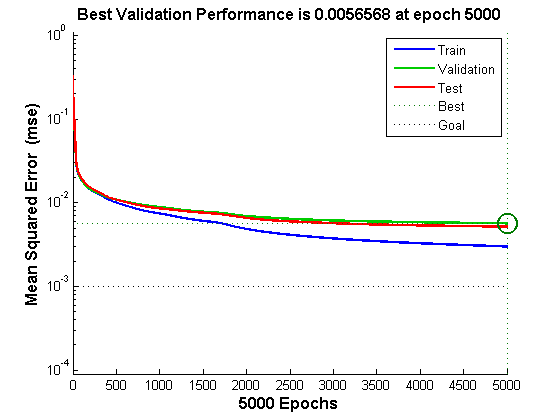
4. Use 544 images, segmented into 2648 symbol images for testing. Get testing accuracy of 87.84%.
5. I also tried 2 hidden layer network, which performs not as well as 1 hidden layer network. Since the input layer is 100 dimensional, and output layer is 41 dimensional, there is not much need to add 2 hidden layers, which increases the network complexity a lot. If the input layer is of high dimensional, like 1000 or so, 2 hidden layers may be necessary in this case.
Conclusion and Future Scope
In this project, the scene images are preprocessed and segmented into isolated characters. Each individual character image is resized and normalized to a binary matrix. Then both unsupervised and supervised learning methods are used to do training and testing. The unsupervised learning algorithm works not as well as supervised methods. The main reason is that the sample image set I created is of limited size and character fonts. It's not possible to capture all the possible situations since the segmented characters may be distorted seriously. The KNN method with cosine distance is very simple and works well. Using neural network to do training and testing also works well, but it has several shortcomings. Firstly, the performance is very sensitive to the network structure and simulation parameters. It needs many trials to find the appropriate transfer functions from input layer to hidden layer, and from hidden layer to output layer. The number of hidden neurons is also difficult to decide. Furthermore, the values of learning rate and momentum are crucial to get good performance. The system is very easy to reach a local minimum.
Currently, the weight updating process has only one momentum term, which adds a weighted emphasis on the previous weight change. For the future work, the process can be modified by adding one more momentum term, as proposed in [2] (see the updating equation from [2] below), to see if a better performance can be achieved. 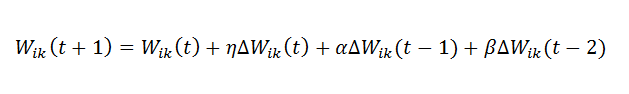
References
[1] Hakan Caner, H. Selcuk Gecim, Ali Ziya Alkar, "Efficient Embedded Neural-Network-Based License Plate Recognition System", IEEE TRANSACTIONS ON VEHICULAR TECHNOLOGY, VOL. 57, NO. 5, SEPTEMBER 2008.
[2] Amit Choudhary, Rahul Rishi, Savita Ahlawat, Vijaypal Singh Dhaka, "Totally Unconstrained Handwritten Character Recognition using Improved BP Neural Network", International Journal of Information Technology and Knowledge Management, Volume 2, No. 2, pp. 645-649, July-December 2010.
[3] Galina Rogova, "Combining the Results of Several Neural Network Classifiers", Neural Networks, Vol. 7, No. 5, pp. 777-781, 1994.
[4] Budi Santosa, "introduction to matlab neural network toolbox", Fall 2002.
[5] Michael Sabourin, "Optical Character Recognition by a Neural Network", Neural Networks. Vol. 5. pp. 843-852. 1992.