Decoding reCAPTCHA
Project team:
- Curtis Jones
- Jacob Russell
Project Review
Our project is on solving reCAPTCHA puzzles. A reCAPTCHA is an image containing two words, one for which the computer knows the solution, and one which normal OCR algorithms gave a low probability of being correct. The idea behind CAPTCHAs is that they solve two problems at once, discriminating between humans and bots, and solving the most difficult word recognition problems.
Preprocessing
Preprocessing is an important step in any CAPTCHA decoding application. Once the word has had any deformations removed, and the letters are segmented, then it's only a matter of determining the features of each letter to determine what classification should be used.
In our project we were faced with two major preprocessing challenges. The first was the presence of an "ellipse" which would locally invert a portion of the image. The second is the segmentation of the letters.
Ellipse detection and removal
Modern reCAPTCHAs now include shapes, which are best described as "ellipses", which are arbitrarily placed in the reCAPTCHA. Where ever this ellipse occurs the pixels are inverted. This compounds the problem of edge detection since a letter and an ellipse may share an edge and the letter's edge profile may change at some point in the letter. Ultimately, any ellipse should be removed to try and improve the overal image so that proper observations can be taken.
Our application uses a very simple density search to determine if an ellipse is present, and then basic neighborhood search to remove it.
The density search is done using a sliding window which takes a snapshot of the pixel density at that location. It then compares that density to that of the entire image.

If the ratio of comparison is over 1.5 then we assume that an ellipse is present at that location and we proceed to try and remove it. Below is an example of an ellipse removal.
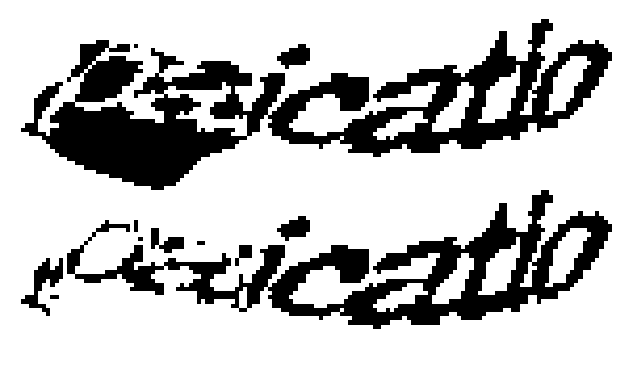
This algorithm has approximpately 75% accuracy using our training images.
Segmentation
Segmentation is the process of splitting up the words into letters. This is one of the most important parts of word recognition, and also where we ran into real problems.
The literature recommended Color Filling Segmentation to segment the images. This approach, which was previously used with CAPTCHAs, did not work for us to segment our reCAPTCHAs because the letters are too close together (and CAPTCHAs have been updated, so they're not the same type of images).
Matlab has a built in function to segment letters based on connected components. This segmentation approach didn't work for us either because of the same reason.
What we actually ended up doing is choosing fixed window sizes and using the fixed window sizes for the moment because it's not the focus of the project.

Unfortunately, this leads to not so great training examples, which in turn leads to bad classification.
Descriptors
Descriptors are needed to describe what our image looks like to the HMM. The HMM itself is supposed to learn the patterns in the sequence of the descriptor, and then associate that pattern with a classification (or classification sequence).
Pixel Sums
We sum the black pixels in the column for each letter and use the column sum vector itself to describe our image.
Note: important to this descriptor is that we can't have much noise in the image. This makes preprocessing (especially ellipse detection and removal) particularly important.
The idea behind this descriptor is that (since we are using a sequence classifier) we are capturing a simple relationship between sequences of columns. This relationship is then assumed to be representative of the image itself.
This descriptor is weak but it enabled us to begin HMM implementation with some form of data without having to sort through implemenation issues possibly caused by more advanced descriptors.
Histogram of Oriented Gradients (HOG)
Once our training implementation was complete we moved toward a more advanced image descriptor. We decided to use HOG since it relies on grayscale images and a large majority of our reCAPTCHA images are also grayscale.
Furthermore, regardless of image size the HOG algorithm would return an observation vector that was 1-by-81 which would work as a form of dimensional reduction. It would also let us use dynamic window sizes over the images when making observations instead of limiting ourselves to a fixed observation window width.
Algorithms
Our original intent was to use Support Vector Machines (SVMs) or K-Nearest Neighbor classifiers (KNNs) because they were recommended in our literature review. Since we are implementing both of these approaches in class, we needed to choose a different classifier. We settled on an Hidden Markov Model (HMM).
Unsupervised
Among the most famous HMM algorithms is an algorithm called the Forward-Backward algorithm (also called Baum-Welch) which is an unsupervised training algorithm that takes in a vocabulary (V), a guess at two matrices (A and B), a set of observations (O), and a guess at a prior distribution (Π) and returns a new transition matrix (A), a new likelihood matrix (B), and a new prior (Π).
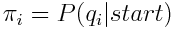
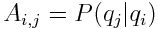
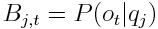
The A matrix represents the probability of the current state given the last state. B represents the probability that we observe our observation given the current state. Because we estimated these values, we need to correct them, and we can do this by estimating the forward probability, or the probability of transitioning to any state by counting our transitions and how likely our transitions are, and simultaneously estimating our backward probability, or the probability of being in the state we are in. Using these, we can count the number of times we're both in a state, and our number of transitions, recompute our probabilities, and iterate until we converge.
After using Forward-Backward for training, one then uses the forward probability going through all of the observations to find a most likely output state (in our case a letter if we use the pixel sum descriptor), or use the forward backward algorithm to get the path that we travel through, and this can be passed in to another HMM to learn words.
Modified Unsupervised
Convergence using the Forward-Backward algorithm can be slow if the initial guess is not good enough, but if you make a good enough guess, then you've already estimated the probabilities fairly well. We go through and count our probabilities (thereby producing one iteration of the forward backward algorithm) and try to use this as a model.
Supervised
Since we have the labels for our training set we can leverage them to help train the HMM. We did this using simple counting to determine the probabilities in the prior, transition, and emission matrices based on the observations provided by the HOG algorithm.
In this case we started by segmenting each image based on the number of letters in the label. This results in a very rough segmentation of the word. Each segmentation is then split into 3 snapshots and each snapshot is fed into the HOG algorithm to retrieve a description of that snapshot. Each HOG description is mapped to a cluster index using K-means, and that cluster index is used when incrementing the emissions matrix.
The transition matrix was initialized using the labels and the transitions between them. The prior matrix is initialized using the first letter of each label.
Modified Supervised
Like the traditional supervised method this algorithm segments the images according to the number of letters present in the label. However, the observations are based again on the colum-sum of pixel values used in unsupervised training.
The modification in this method is how the transition matrix is initialized. The emission matrix provides the best possible state the HMM will be in based on an observation. Therefore, that state is used to determine what the next state will be that the HMM transitions to. This is counted in the transition matrix and the probabilities are found based on the observations used to build the emission matrix.
Viterbi
After training is complete the testing images are evaluated against the HMM using a Viterbi algorithm. The algorithm works by choosing the most probable path through the HMM at each observation point. The result is a probability that the observation vector corresponds to a given path through the HMM. This path result is used to determine the letter, or letters, the observation vector describes.
Results
Results to date have been limited to the Modified Supervised and Supervised methods.
The modified supervised method was able to correctly classify 0.4% of the letters. Unfortunately, it was unable to classify words or any complete reCAPTCHA images.
The supervised method was able to classify 5.2-6.1% of individual letters and 17-28% of word lengths. The testing phase was not informed to what the length of the words was. Unfortunately, it was only able to classify 1 word of 100 and couldn't classify any compelte reCAPTCHA images.
Status
We believe that we are on track despite not coming close to our milestone goal of 50%. We believe that our 50% figure was unrealistic because it assumed many of the external algorithms that we were relying on would work. One example being segmentation which would give us good training data turns out to be infeasible using other methods that were supposed to work from the literature. The models that we have been training, use simple descriptors, and we could gain benefits by combining descriptors or using more advanced ones.
Future Work
Due to the complexities of our training and test set we've decided to seek a new one what does not require removal of shapes, and one that will allow easier segmentation of characters whether through straight line segmentation or middle-axis segmentation. If necessary we may hand-label individual letter locations to aid the HMM training.
We are also working to reduce the complexity of our observation space which is well over 700 different possible observation vectors. This has resulted in very low probabilities in our algorithms which could be improved by reducing the number of observation classes through use of K-means clustering.