We address the problem of handwritten character recognition. There are numerous applications in which automatic detection of handwritten characters and digits would have tremendous utility. One example is that of automatically recognizing characters in hand-printed forms [3]. By applying modern machine learning techniques like neural networks to this problem, we achieve error rates under 5%. In particular, we consider back-propagation networks.
We use the MNIST (mixed NIST) database which, as the name implies, is a mixture of two different databases, NIST-SD 1 and NIST-SD 3 (MATLAB version acquired from [2]). It comprises a total of 70,000 greyscale images of digits with corresponding labels : 60,000 for training and 10,000 for testing. Raw images were normalized to occupy a 20 pixel x 20 pixel bounding box. These were then centered to fit inside a 28 pixel x 28 pixel via center of mass computations. The data set itself has been used in numerous papers over the years and seems to be a good choice.
It may be worth mentioning that the first 5,000 test samples of MNIST are supposed to be easier to classify than the last 5,000. This is because the first 5,000 samples were taken from NIST-SD 3, a database of digits written by Census Bureau employees, while the last 5,000 were taken from NIST-SD 1, a database of digits written by high school students. This, discrepancy in perceived ease of classification also seems somewhat interesting to look at.
Above is an example of entries in the MNIST database.
We approach the problem with back-propagation networks. [5] and [6] provide good primers on the subject. Multiple architectures for back-prop networks have been used in the literature. We consider back-propagation networks of 1 and 2 hidden layers respectively. The 1-hidden layer back-prop network we tested comprised 784 input nodes corresponding to each of the 28x28 pixels, 300 hidden nodes, and 10 output nodes corresponding to each of the 10 digits. The 2-hidden layer back-prop network we tested comprised 784 input nodes, 300 hidden nodes in the first hidden layer, 100 hidden nodes in the second hidden layer, and 10 output nodes. For our activation function we applied the sigmoid function. Our code, however, is quite flexible and we can easily explore other configurations of 1-hidden layer and 2-hidden layer back-propagation networks. It would also not be too difficult to add additional functionality for 3-hidden layers. However, we believe our time would be better spent exploring other avenues.
For our activation function, we use the familiar sigmoid function. Our implementation employs the technique of gradient descent for back-propagation. Our general back-prop algorithm is summarized in [12]. In addition to a basic implementation of back-propagation networks of 1- and 2-hidden layers, we do training over multiple epochs, use a linear function of the current epoch to choose alpha values for gradient descent, and analyze misclassification on a per digit basis.
After implementing the basic structure of our ANN, we first set out to test it using a single hidden layer of nodes. We experimented with various alpha values and epochs (number of times the training set was trained on). As of this milestone, we have had the most success with an alpha value of 10^-3 and as many epochs as we can run. We have maanged to test up to 16 epochs, but this took around 8 hours to complete. The error rates for our single hidden layer testing is shown below.
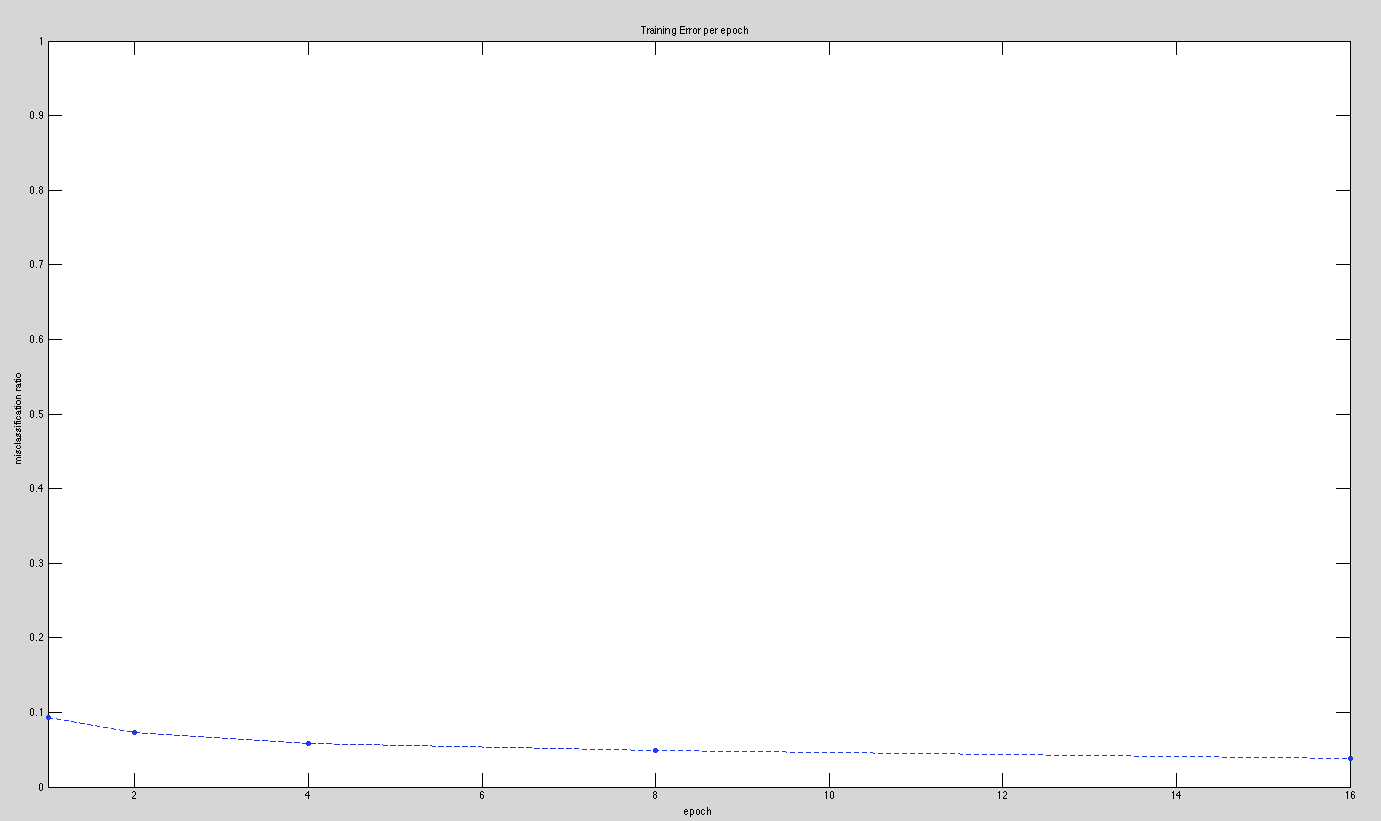
For a single hidden layer of nodes, we obtained the following data:
1 epoch: 9.31% Misclassification
2 epochs: 7.26% Misclassification
4 epochs: 5.89% Misclassification
8 epochs: 4.87% Misclassification
16 epochs: 3.81% Misclassification
We then attempted to get results when using 2 hidden layers instead of 1 for epochs ranging from 1 to 8, which resulted in the following error rates:
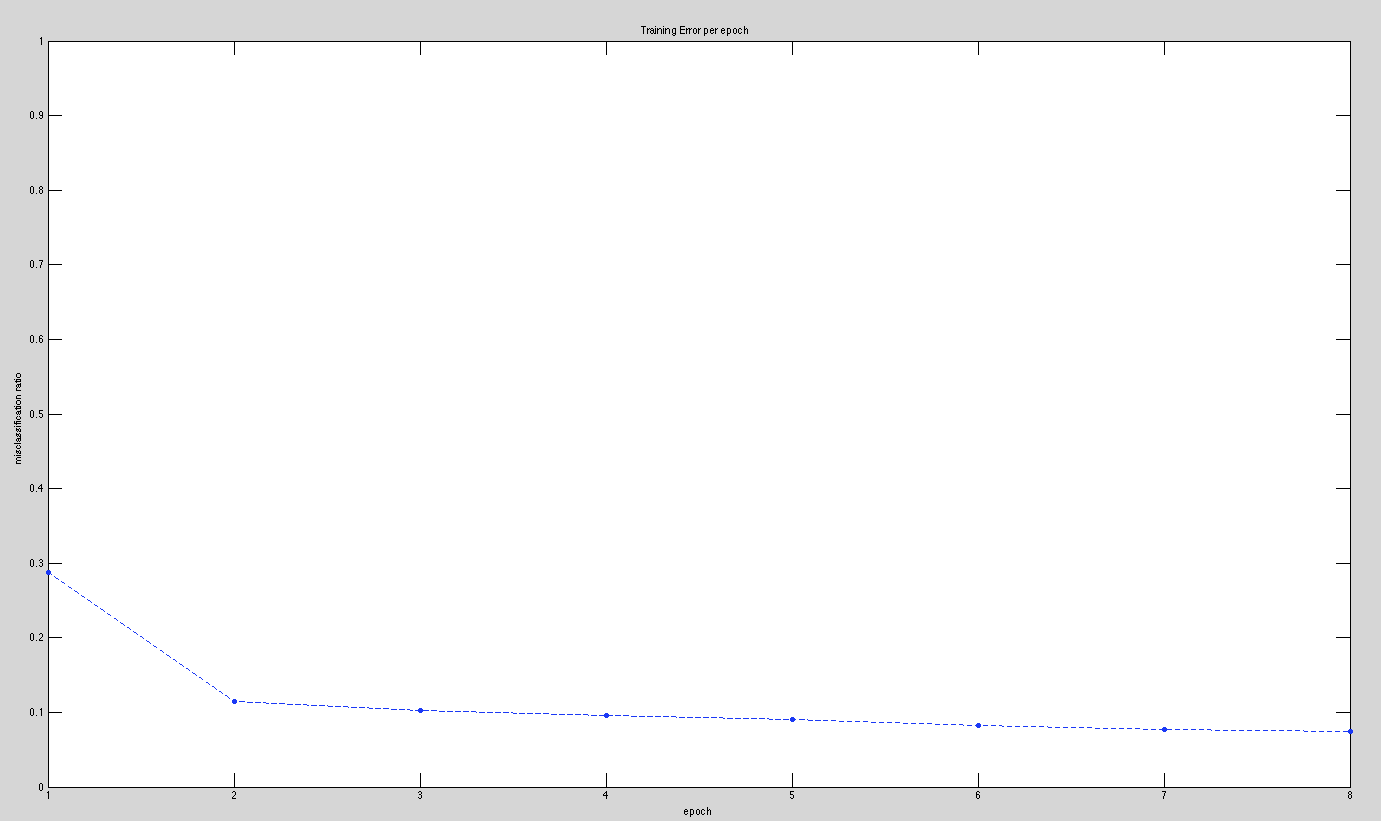
For 2 layers of hidden nodes we obtained the following data:
1 epoch: 15.46% Misclassification
2 epochs: 11.18% Misclassificiation
4 epochs: 8.15% Misclassification
8 epochs: 6.39% Misclassification
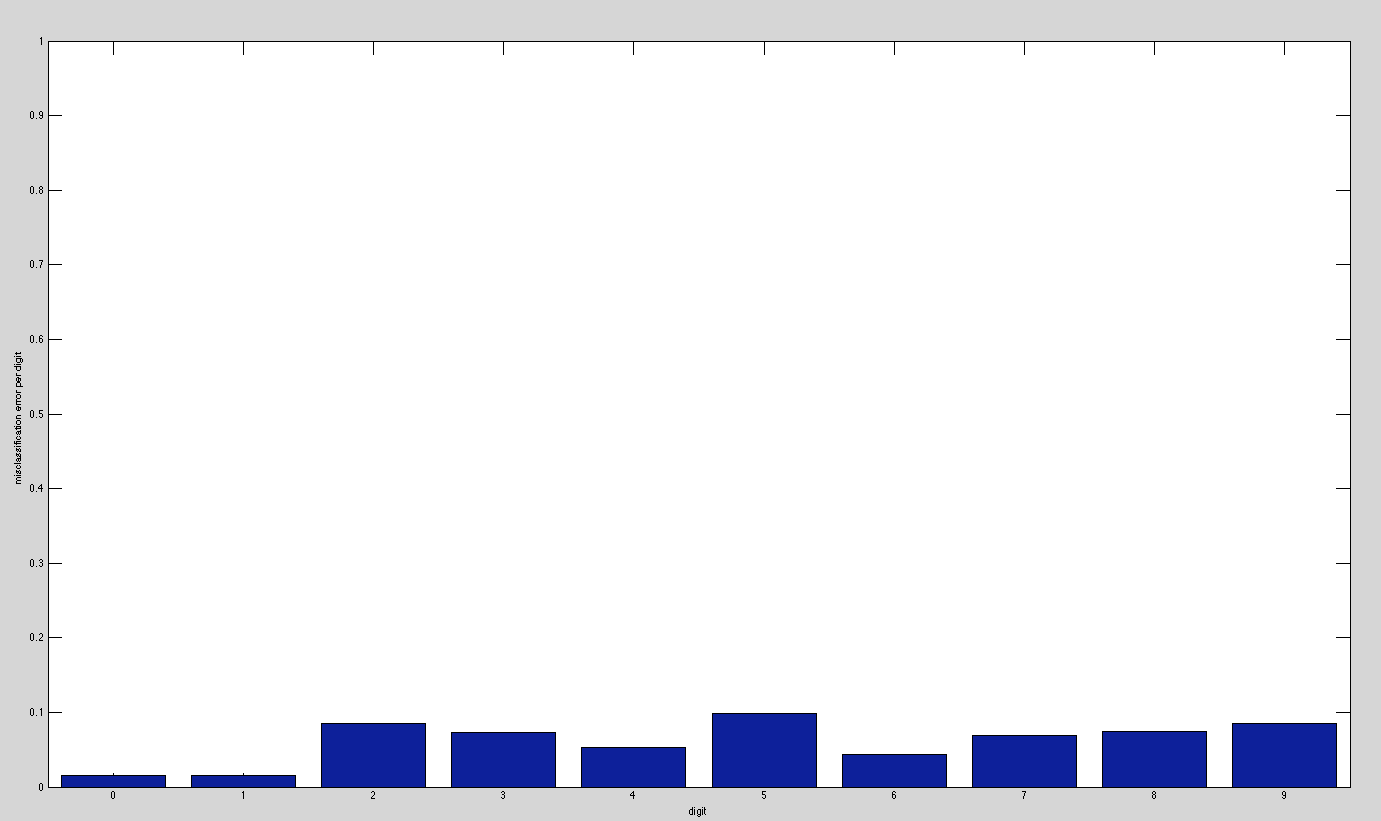
The error rates that we got for 2 hidden layers was higher than we expected, and we will continue to look into this in the coming weeks. We feel that our implementations for both 1 and 2 hidden layers are fundamentally sound, but can still be tweaked to obtain even better results. We have started to look into ways to reduce the error that we receive and have very recently started to analyze the error on a per-digit basis. When training on our test set for 2 hidden layers, we recorded which digits were misclassified, which we show in the graph below. We plan to use this data to make adjustments in the coming weeks.
We believe we've achieved the vast majority of our milestone goals. We have progressed at the rate we had hoped with respect to our original projected timeline that was we proposed, and we have already exceeded our goal of attaining 95% classificaiton correctness. To our knowledge, we have a solid implementation of back-propagation networks of both 1-hidden layer and 2-hidden layers. We've also done some preliminary analysis and have coded in a way that allows for further analysis to be done with ease. However, we are still considering improvements and optimizations.
Over the coming weeks we have a few objectives. First, we would like to determine if there's a better way to set alpha than the approach we're using. We would also like to see how shape contexts fare with back-prop networks. If time permits, we'd like to consider metric learning with k-NN or possibly convolution networks to solve this problem as well. However, this may be a little bit ambitious given the remaining time. If we feel we cannot succeed at implementing a new method, we may just look at other preprocessing methods to improve our results, such as width normalization and deskewing, and/or apply algorithms we've implemented in homeworks to the problem for comparison. The technique of momentum as discussed in [8] would also be interesting to look at. We hope to achieve a significant subset of the goals above in the next two weeks. Last, but most important, we believe the remaining week will be sufficient to finish any minor pending analysis, construct the poster, and to do the writeup.
[1] Yann LeCun, Corinna Cortes, The MNIST Database.
[2] Sam Roewis, Data for MATLAB hackers.
[3] Wikipedia, Intelligent Character Recognition.
[4] Ivan Galkin, Crash Introduction to Artificial Neural Networks.
[5] Christopher M. Bishop, Pattern Recognition and Machine Learning, Chapter 5.
[6] Stuart Russel, Peter Norvig, Artificial Intelligence : A Modern Approach. Second Edition. Sections 20.5 and 20.7
[7] Bobby Anguelov, Taking Initiative, Basic Neural Network Tutorial - Theory.
[8] Bobby Anguelov, Basic Neural Network Tutorial - C++ Implementation and Source Code.
[9] Christos Stergiou, Dimitrious Siganos, Neural Networks.
[10] Simon Dennis, BrainWave 2.0, The BackPropagation Network : Learning By Example.
[11] Herman Tulleken (?), 15 Steps to Implement a Neural Network.
[12] Lisa Meeden, Derivation of Backpropagation.