Intersection Traffic Detection
Lamia Iftekhar
TASK
This project is an application of supervised learning algorithms. We propose to detect traffic at an intersection based on image data captured on a traffic camera.
DATASET
The dataset used for this project is obtained from the Hanover Police Department[1]. It is a collection of still images taken from a single traffic camera mounted on the Lyme/ North Park intersection near Dartmouth Medical School. The database contains daytime images from two consecutive weeks during Jan/Feb 2012. The images are taken from 8am to 4pm.

Figure 1: A sample image from the dataset
APPROACH
We are following the Viola-Jones face detector method [2] to detect vehicles from the image. Although this method was originally designed to detect faces, the concept presented in the paper can be applied to detecting objects of other kinds provided suitable modification is done at the feature selection part. Several papers have demonstrated so in the context of vehicle detection [3],[4],[5]. But all of these works only focused on images of the front or rear view of the vehicles. On the other hand, our images includes vehicles from various angles due to the location of the camera and the fish-eye view. For example, the vehicles on the right of the intersection are seen from the top mostly, whereas the vehicles coming down from the top road are seen more from the side. Also, the size of the vehicles are highly distorted depending on their position in the image.
METHOD
The Viola-Jones framework described in [2] has three important characteristics :- its feature selection process based on integral images and Haar-like features: sums of image pixels within rectangular areas
- its learning method based on training weak learners and blending their outputs to make a strong classifier
- its 'attentional cascade' structure where false postive rates are achieved by using simpler classifiers to quickly reject majority of the negative sub-windows of the image before complex classifiers focus near the regions that have vehicles to detect.
The Viola-Jones detector uses Adaboost for both feature selection and learning. The early features chosen by Adaboost are meaningful. For example for face detection, Haar-like objects such as those shown in Figure 2 are chosen and they may represent the contrast between the eyes and nose or the eyes and cheeks. For vehicle detection similar features may represent the dark region underneath a car or the two tires (Figure 2: right) .

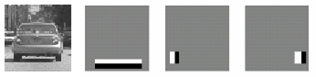
Figure 2: Haar-like features. (left) used in [2] , (right) used in [3]
The cascaded structure builds on the premise that when scanning an image for vehicles, the detection speed can be increased if negative regions are quickly discarded using initial classifiers and more complex classifiers only focus on the more promising regions of the image.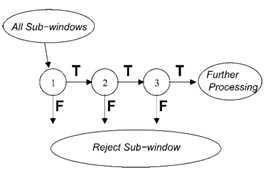
Figure 3: Depiction of detection cascade from [2]
PROGRESS SO FAR
Data Processing
We built a database of positive examples by cropping many of the distinct vehicle regions in the images in our dataset. The negative image database were built by cropping regions of empty road and surroundings from the images in our dataset. These cropped images were then all turned to grayscale images and histogram equalized. Also the image sizes were normalized to the same size, 40 x 60 pixels, for ease of Adaboost learning.

Figure 4: Some positive and negative examples
Implementation of Basic Adaboost
We implemented the basic concept of Adaboost to train some weak classifiers on a majority of our data (obtained as above) and validated the resulting strong classifier on the remaining small portion of the data. Instead of using weak classifiers based on Haar-like features, we opted for simpler weak learners to quickly observe the performance of the boosted learning method. The weak classifiers chosen are simple tree stumps based on the variance in each image. We focused on data obtained from the right portion of the images in the original dataset ( the road on the right of the intersection). Multiple instances of this rudimentary test yielded, on average, a 40% error rate by the classifiers learnt through this boosting method.
MILESTONE STATUS AND THE WORK AHEAD
In our project proposal, we had planned to finish all training and testing by milestone. Unfortunately, the Viola-Jones detector has multiple levels of complexity that wasn't taken into account during the proposal and implementing it on MATLAB from scratch without the help of OpenCV has proved nontrivial. The main Adaboost algorithm of the Viola-Jones detector is nevertheless taken are of and the focus would be on implementing a detector that is as similar as possible to the concept described in [2]. Because of the difference in the vehicle features at different parts of the intersection ( the Haar-like features may differ, such as vehicles on the top road may require diagonal Haar-like features), we plan to train four different detectors for the four road regions.
Figure 5: Four road regions
REFERENCES
- Thanks to Lt. Michael Evans of Hanover Police Department.
- Paul Viola and Michael Jones, “Robust Real-time Object Detection” International
Journal of Computer Vision (IJCV), 2004. - David C. Lee, and Takeo Kanade. "Boosted Classifier for Car Detection." 2007.
- J.-H. Kim, H.-C. Jung, and J.-H. Lee, "Improved AdaBoost learning for vehicle detection," Int. Conf. on Machine Vision, pp. 347-351, Dec. 2010.
- Jong-Min Park; Hyun-Chul Choi; Se-Young Oh; , "Real-time vehicle detection in urban traffic using AdaBoost," Intelligent Robots and Systems (IROS), 2010 IEEE/RSJ International Conference on , vol., no., pp.3598-3603, 18-22 Oct. 2010