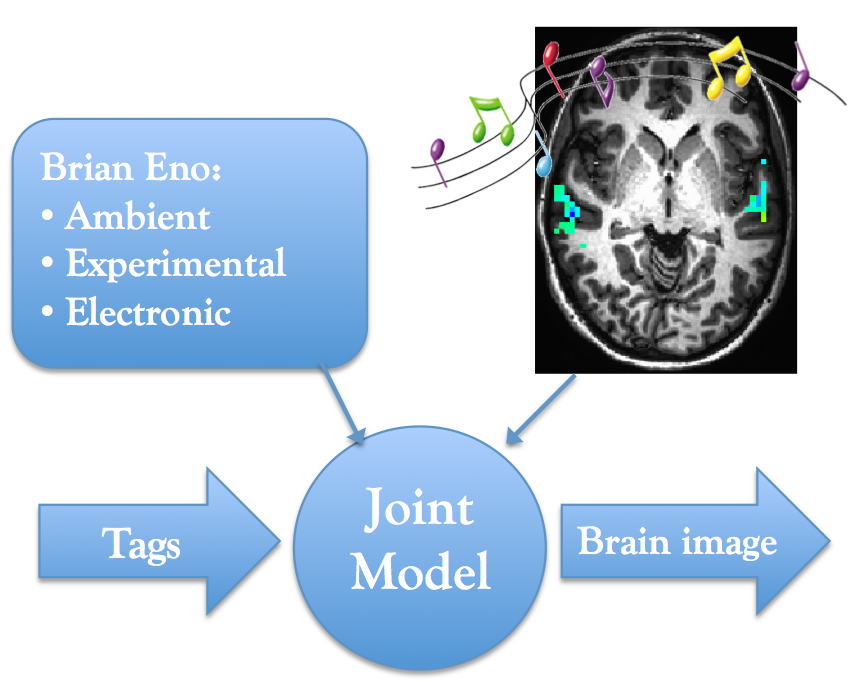
 Figure 1. Overview of project goals. Train a joint model such that brain images can be predicted from tag vectors.
Figure 1. Overview of project goals. Train a joint model such that brain images can be predicted from tag vectors.Progress
In my project proposal, I set the following goals for myself to accomplish by the milestone update:
- Collect and analyze tags. Select a subset to use as dictionary.
- Prepare and reduce dimensionality of brain features using anatomical masks and SVD.
- Implement J. Weston's WARP loss optimization algorithm in python
Tags
Tags were pulled from last.fm using a hierarchical search. Tags were collected in the following order:
- Tags for the exact track
- Artist tags
- Tags of similar artists
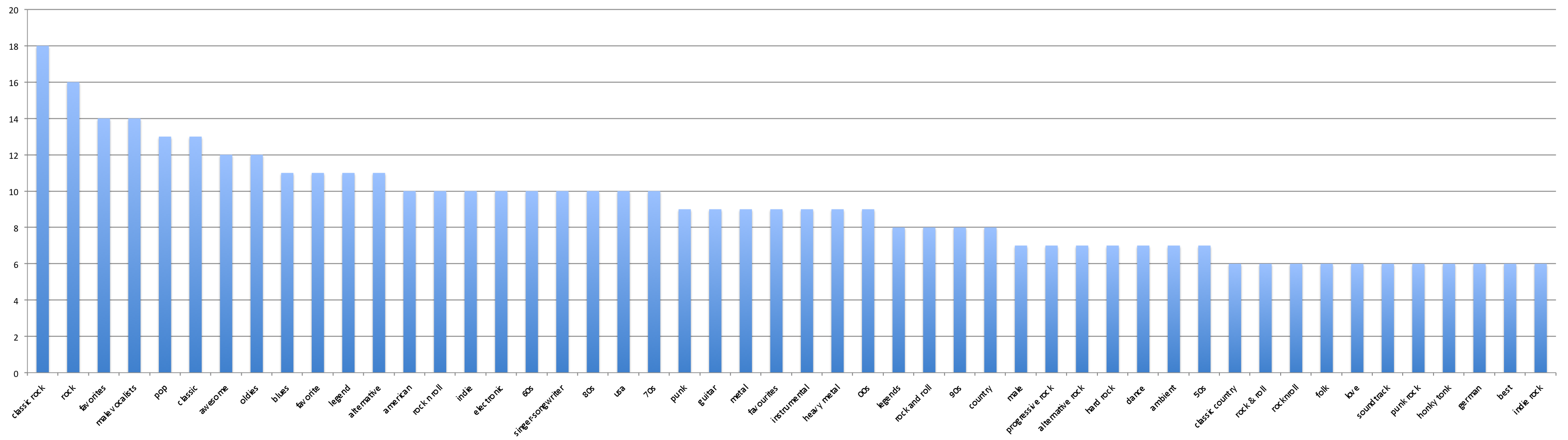 Figure 2. Histogram of occurrences of 50 most popular tags across the 25 stimuli tracks. Note that the most popular tag "classic rock" appears for 18 out of the 25 tracks.
Figure 2. Histogram of occurrences of 50 most popular tags across the 25 stimuli tracks. Note that the most popular tag "classic rock" appears for 18 out of the 25 tracks.The WARP loss optimization algorithm optimizes precision at the k top rank annotation positions. This is sometimes written as "p@k". If k=1, then the algorithm optimizes precision at the top ranked tag. So I decided to inspect the top ranked tag for each track. This is summarized in Table 1.
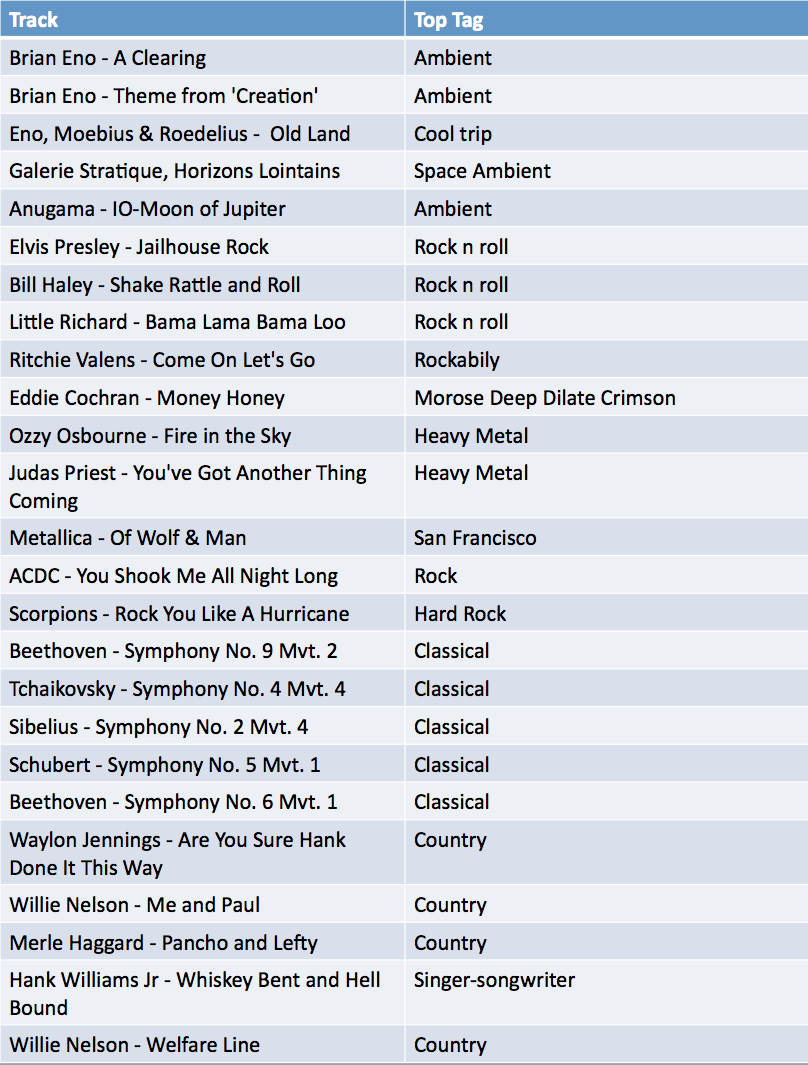 Table 1. Top last.fm tags for each of the 25 musical stimuli. Yes, "Morose Deep Dilate Crimsom" is a real tag
Table 1. Top last.fm tags for each of the 25 musical stimuli. Yes, "Morose Deep Dilate Crimsom" is a real tagBrain Features
Anatomical masks of the STS were applied to whole-brain BOLD data for each participant. The dimensionality of these features were further reduced using singular value decomposition (SVD). The application of anatomical masks and extraction of components via SVD reduced the dimensionality of the features from 224,000 to approximately 500, depending on the subject. The resulting features are saved in one 600 x D matrix per subject where D is the dimensionality of the reduced brain features and 600 is the number of observations per subject.
WARP Loss Optimization Algorithm
I used the description from Weston 2011, especially the pseudo-code in Figure 3, to implement the WARP loss optimization algorithm in python, shown in Figure 4.
 Figure 3. Pseudo-code for the WARP loss optimization algorithm described in Weston 2011.
Figure 3. Pseudo-code for the WARP loss optimization algorithm described in Weston 2011.
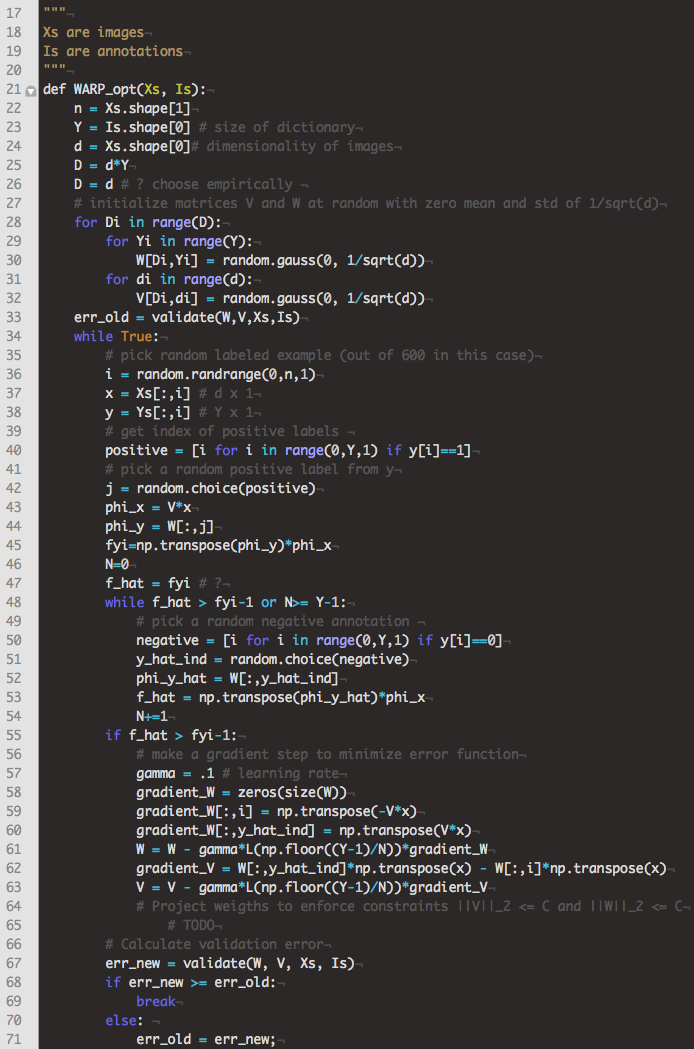 Figure 4. Python implementation of the WARP loss optimization algorithm described in Weston 2011.
Figure 4. Python implementation of the WARP loss optimization algorithm described in Weston 2011.Future Work and Discussion
As planned in the project proposal, model evaluation will be conducted after the milestone. This will involve the leave-two-out retrieval experiment described in the introduction.
After implementing the above learning method and reading further material on the topic, I wonder if my data is not appropriate for the WARP loss optimization algorithm. Although I have 600 examples per subject, these 600 are repetitions of the same 25 stimuli, thus I only have the tags for 25 tracks to work with. Additionally, the top ranked tags for the 25 tracks are severely overlapping (e.g. the top track for all romantic symphonies is "classical"). Since the WARP algorithm is optimizing p@1, it seems I am only going to be able to learn coarse, high-level categorizations of the stimuli. I was originally hoping to take advantage of the long lists of tags for each track and the probabilities associated with each tag to access finer detail about the brain's response to the music. Ultimately I would like to be able to use my trained model to predict brain activity from a previously unseen combination of tags or from single tags. It recently occurred to me that I have access to another similar dataset of fMRI data that could be useful. This second dataset was collected as a follow-up study to the study from which my original brain data came. In this study, participants were exposed to country music with and without voice and with and without percussion and ambient music with and without voice and with and without percussion. This study was conducted on new subjects, though, so I wouldn't be able to easily combine the two datasets without transforming all brains to a common space and adjusting anatomical mask sizes. Perhaps given the short time scale, I will continue with the WARP algorithm and my current dataset, but ultimately I would like to be able to take advantage of the variation in the tail of the tag lists for each track to learn details about their representation in the brain. For example, consider two tracks whose top two ranked tags are "Country" and "Acoustic", but the third top ranked tag of one is "male vocalist", while the third top ranked tag of the other is "female vocalist". I want my model to be able to learn this difference and accurately predict any differences in brain activation.
References
- Casey, M., J Thompson, O. Kang, and T. Wheatley. Population codes representing musical timbre for high-level fMRI categorization of music genres. In Springer Lecture Notes on Artificial Intelligence (LNAI) - Survey of the State of The Art Series. Springer, 2012, In press.
- Mitchell, T.M., S.V. Shinkareva, A. Carlson, K.M. Chang, V.L. Malave, R.A. Mason, and M.A. Just. Predicting human brain activity associated with the meanings of nouns. Science, 320(5880):1191–1195, 2008.
- Staeren, N., H. Renvall, F. De Martino, R. Goebel, and E. Formisano. Sound categories are represented as distributed patterns in the human auditory cortex. Current Biology, 19(6):498–502, March 2009.
- Usunier, N., D. Buffoni, P. Gallinary. Ranking with ordered weighted pairwise classification. In Proceedings of International Conference on Machine Learning. 2009
- Weston, J., S. Bengio, P. Hamel. Large-scale music annotation and retrieval: Learning to rank in joint semantic spaces. Journal of New Music Research, 2011.
- Weston, J., S.Bengio, and N. Usunier. Wsabie: Scaling up to large vocabulary image annotation. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), 2011.
- Weston, J., B. Scholkopf, and O. Bousquet. Joint Kernel Maps. in Predicting Structured Data. Springer-Verlag, pp.176–191, 2005.