Calculate the covariance coefficients r of the test image and all the sample images. Pick the label that has the largest r.
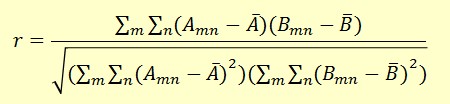
Use 544 images, segmented into 2648 symbol images for testing.
Accuracy: 73.19%
Accomplishment
1. Image preprocessing
2. Word segmentation and normalization
3. Word recognition using unsupervised learning
4. Word classification using supervised learning
Image Preprocessing
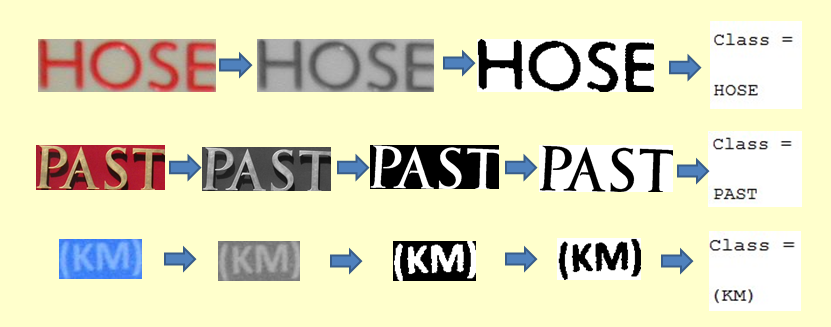
1. Sharpen the image when necessary. For blurred images, sharpening is needed to better detect the edges and find the threshold. The method I used is based on the gradient of the image. After sharpening, the original region with smoothing grayscale doesn't change much, while the ones with steep grayscale become steeper, so as to enhance the image details. Here's an example.
2. Convert RGB image to grayscale by using Matlab function rgb2gray().3. Calculate the threshold using OTSU algorithm and S.Watanabe Algorithm, based on image histogram. For my dataset images, the OTSU method works better.
4. Convert grayscale images to black and white, according to threshold, by setting the pixel one if it is greater than the threshold, and zeros otherwise.
5. Determine the background of the image and change all images to black characters with white background. This is easier for the next segmentation process.
Word Segmentation and Normalization
1. Segment the words based on region connection. Scan the image from left to right, up to down, label the pixel by looking at the four processed neighbors, then resort the labels by inversely scanning the image. For example,
2. Remove the non-character section by eliminating the labeled region that is below the 100 percent of the image area.3. Cut the image into individual characters and normalize each isolated character to 42*24 size.
Below are some examples of the process.

Supervised Learning
Use KNN classifier with cosine distance.
Use 596 images, segmented into 3195 symbol images for training. Use 544 images, segmented into 2648 symbol images for testing.
Accuracy: 92.87%
Below are some examples of the process.
Unsupervised Learning
Create 70 sample symbol images.

Calculate the covariance coefficients r of the test image and all the sample images. Pick the label that has the largest r.
Use 544 images, segmented into 2648 symbol images for testing.
Accuracy: 73.19%
Shortcommings
1. Unsupervised learning method works poorly on images with distorted characters, since the samples are standard. Furthermore, the test set images are of various fonts. This also limits the performance of this unsupervised learning method, since the number of samples is limited. It is not practical to take every font of each character into the sample set.
2. Segmentation algorithm is not robust enough. Words that are connected seriously can not be effectively segmented. See the images below for example.
Future Work
1. Create neural network with 10 hidden neurons and 70 outputs. Use back-propagation to train and test the network.
2. Try Holistic classifier, which is to treat the word image as a whole, detect the edges and do classification.
References
Shahab, Asif; Shafait, Faisal; Dengel, Andreas; , "ICDAR 2011 Robust Reading Competition Challenge 2: Reading Text in Scene
Images," International Conference on Document Analysis and Recognition (ICDAR), 2011 , pp.1491-1496, 18-21 Sept. 2011
Otsu's method for histogram shape based image thresholding, wikipedia.
Vassilis Papavassiliou, Themos Stafylakis, Vassilis Katsouros, George Carayannis, "Handwritten document image segmentation into text lines and words", Pattern Recognition 43 (2010) 369-377.
Zhou Yue, Yan Feng, Zhang Mingchao, et al, "Algorithm for connected component labeling of binary image based on label transmitting", Computer Engineering and Application, 45(33):153-155, 2009.