Feature Combination for Multiclass Object Classification
With Clustered Dataset
Peng Wang
COSC 174 - Machine Learning and Statistical Data Analysis
Spring 2012
Problem Statement
Multiclass object classification is a difficult problem due to high variability of visual appearance within each class. A key element is to design a robust identification of relevant class specification in presence of intra-class variations. One possible approach is to adaptively combine a set of diverse and complementary features-such as features based on color, shape-in order to discriminate each class best from all other classes [1].
Inspired by Torralba and Efros's research, I proposed a variation of feature combination algorithm that implements data classification before the hyper parameters selection in the Gehler and Nowzin's approach. We anticipate that pre- data classification will yield a better training result in hyper parameters selection, which will ultimately improve the overall model performance in terms of accuracy. My proposed model is a combination of feature combination for multiclass object classification and a clustered dataset, each of which has an associated weighting of stylistic features.
Progress
So far, I am at what I proposed for the milestone. I finished the data clustering for the original dataset. I still need to implement the LP-beta algorithm for the final step of my project. There are some remaining questions for LP-beta algorithm implementation. But I believe these problems will not be too challenging to solve. I will be on track with the rest of my project.
Model
An important problem when analyzing relational data between features is clustering, finding sets data sets that are "more similar" to each other in the dataset. Here, we implement the spectral clustering algorithm by Andrew NG et al for data clustering [11].
spectral clustering
Three futures are selected for clustering: color, shape and texture. Kernel matrix is defined as: Km=exp(gamma^-1*d(xi, xj)) [1]. Where, gamma is the mean of the pairwise distances, and d is the pairwise distance matrix.
Affinity matrices for color, shape and texture:

Classification error for color (on all training sets):
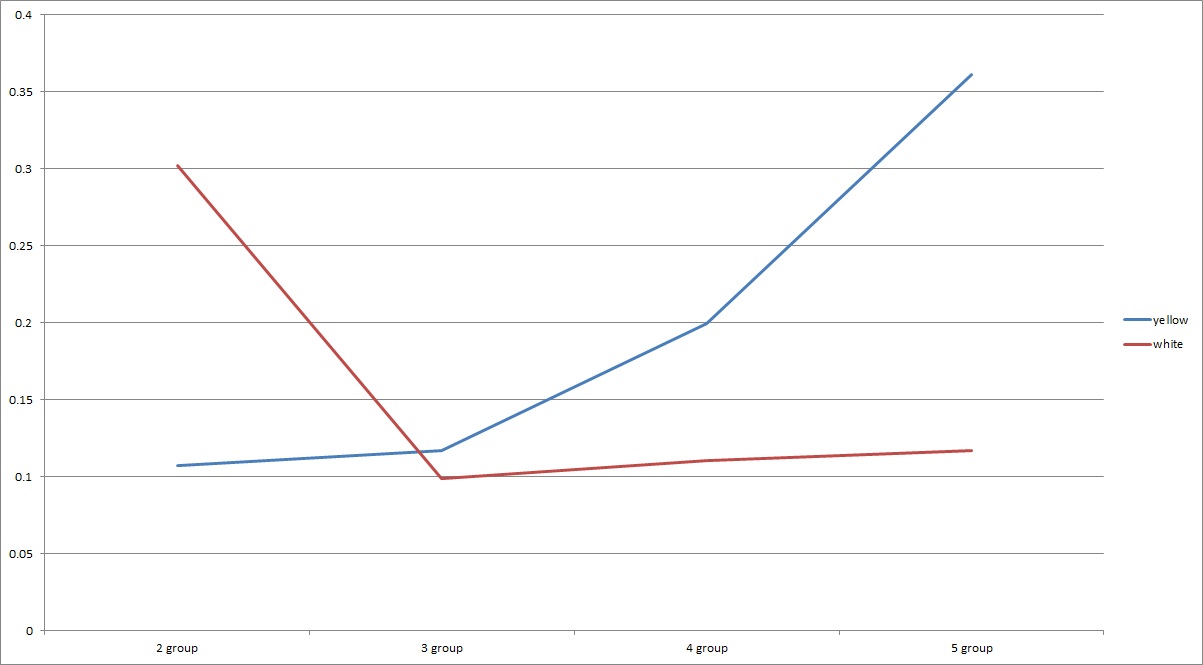
However, there is a open issue in the spectral clustering: how to estimate the number of groups? For feature color, it is possible for me to manually label the data. But it is much harder for me to label the data based on texture and shape. Therefore, it is worth studying a new method to automatically determine the number of groups. Lihi Zelnik-Manor and Pietro Perona [12] proposed a self-tunning spectral clustering algorithm, which will automatically give the number of groups.
Self-tuning spectral clustering
Zelnik-Manor modified the Ng-Jordan-Weiss algorithm by substituting the locally scaled affinity matrix instead of affinity matrix. The resulting algorithm automatically defined a scheme to set the scale parameter, which is used in affinity matrix calculation. By analyzing the eigenvectors, Zelnik-Manor proposed a new method to determine the number of groups automatically.

Next step
For my next step, I will implement the LP-beta, and will then start extensive experiments on the Oxford flowers dataset. There are a number of parameters in the model and learning algorithms. I expect to spend a decent amount of time to optimize these parameters.
Updated hypothesis function for LP-beta algorithm:
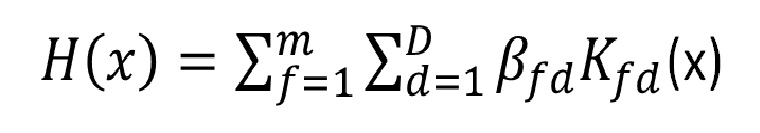
Data
In consistent with Gehler and Nowzin's study, I will apply the method to two data sets: Oxford flowers[4] and Caltech datasets[5, 6]. I might choose some other datasets for preliminary testing.

Updated timeline
Note: Dates above may be subject to change and certain goals may be shifted forward or backward in time depending on progress.
References
- P. V. Gehler and S. Nowozin, "On Feature Combination Methods for Multiclass Object Classification", IEEE International Conference on Computer Vision (ICCV), 2009.
- A. Torralba, and A. Efros, "Unbiased Look at Dataset Bias", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2011.
- A. Bergamo, and L. Torresani, "Exploiting weakly-labeled Web images to improve object classification: a domain adaptation approach", NIPS, 2010.
- M.-E. Nilsback and A. Zisserman. A visual vocabulary for flower classification. In ICCV, pages 1447-1454, 2006.
- L. Fei-Fei, R. Fergus, and P. Perona, "Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories", In CVPRW, page 178, 2004.
- P. V. Gehler and S. Nowozin, "Let the kernel figure it out: Principled learning of pre-processing for kernel classifiers"' In CVPR, 2009.
- L. Duan, I.W.-H. Tsang, D. Xu, and S. J. Maybank, "Domain transfer svm for video concept detection", In CVPR, 2009.
- K. Saenko, B. Kulis, M. Fritz, and T. Darrell, "Transferring visual category models to new domains", In ECCV, 2010.
- J. Yang, R. Yan, and A. G. Hauptmann, "Cross-domain video concept detection using adaptive svms", MULTIMEDIA -07,2007.
- C. M. Bishop, Pattern Recognition and Machine Learning. Springer, 1st ed.,
- A.Y. Ng, M.I. Jordan, and Y. Weiss, On spectral clustering: Analysis and an algorithm. In Advances in Neural Information Processing Systems 13, 2001. October 2007.
- L. Zelnik-manor and P. Perona, Self-tuning spectral clustering, Advances in Neural Information Processing Systems 17, pp. 1601-1608, 2005, (NIPS'04)