Recommendation Prediction in Social Networks
Milestone
Yangpai Liu & Yuting Cheng
1 Goal
We have two subproblems in our project. The goals are as following respectively:
- According to follow history of weibo, predicting whether or not a user will follow an item that has been recommended to the user .
- Predict the click-through rate (pCTR) of ads in Tencent search engine sousou.com
2 Methods
2.1 Subproblem 1: predict whether the user will "follow" the recommendation item.
For this problem, we use KNN algorithm[1]:
if we want to decide if user A will "follow" item I, firstly, we find K nearest neighbor users in training set. Then, we will check if the number of users in the K neighbors who "follows" I is larger than a threshold. If so, the user A will "follow" I. Otherwise, A won't follow I.
Now we need to define the distance between user A and user B. We think the closer the two user are, the larger the similarity between them is.
Let s(A, B) denotes the similarity between A and B. To get s(A, B), we need to introduce several attributes we will use ($a_i$ denotes attribute i and s($a_i$) denotes similarity of attribute i between A and B):
1. First, we extracted and aggregated seven attributes of users we will use[2]
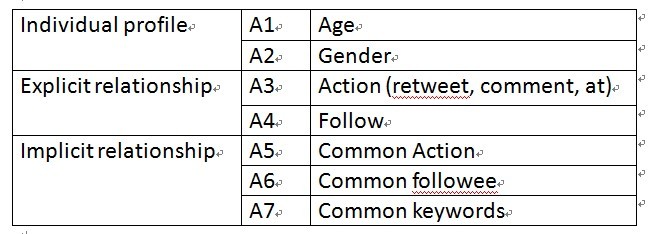
Figure 1. Attributes extracted from the data
Attribute 1: Year of Birth
$s(a_1) = 1-\frac{| yearofbirth(A) - yearofbirth(B) |}{100}$
Attribute 2: Gender
$s(a_2) = 1-| gender(A) - gender(B)|$
Attribute 3: Action
$s(a_3) = \begin{cases}1 & \text{if A takes an action to B or B takes an action to A} \\ 0 & \text{otherwise} \end{cases}$
Attribute 4: Follow
$s(a_4) = \begin{cases}1 & \text{ if A follows B or B follows A} \\ 0 & \text{otherwise} \end{cases}$
Attribute 5: Common Action
$s(a_5)=\frac{\textrm{number of common action objects}}{\textrm{total number of action taken by A and B}}$
Attribute 6: Common Followee
$s(a_6)=\frac{\textrm{number of common followees}}{\textrm{total number of followees of A and B}}$
Attribute 7: Common Keywords
$s(a_7)=\frac{\textrm{number of common keywords}}{\textrm{total number of keywords of A and B}}$
2. Select a subset of the users (neighbors) to use as predictors (recommenders).
We get the subset based on similarity. We define the similarity between user A and user B as follows:
$s(A, B)= \sum\limits_{i=1}^7 w_i*s(a_i)$
3. Get the recommendation result.
If “majority” of the subset follow the item, then we predict the user will also “follow” the item. Otherwise, he/she will not follow the item.
About "majority": We tried to use some constant percentage as threshold to make the decision. It turns out quite bad when we have a bias of train set with some recommendations taken many times. Hence
We develop a way measure the "majority".
First we calculate the frequency of each item i in our trainset freq_i. For the item to handle in testset, we use following rules to get rid of the bias of high frequent items:
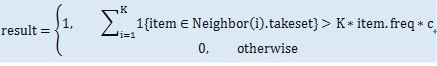
Note that c is a constant scaler used to get right prediction.
3 Results
We designed two benchmark for subproblem 1:
1. Overall Correctness Rate (OCR):
$OCR=\frac{\textrm{number of correct prediction we make}}{\textrm{size of testing set}}$
2. Recommendation Accept Rate (RAR):
$RAR=\frac{\textrm{number of correct "follow" prediction we make}}{\textrm{number of "follow" we make}}$
Test for different attributes groups
In order to evaluate the attributes we extract, we launched a set of test with different attributes set. (i.e. with different w)
We can see that individual methods and the hybrid one (combine three kinds of attributes) have almost the same OCR (Figure 2). However, with hybrid method, we tend to have a higher RAR (Figure 3).
In other words, if we want build a positive recommendation system (make relatively regular number recommendation to users), the hybrid method has better performance.
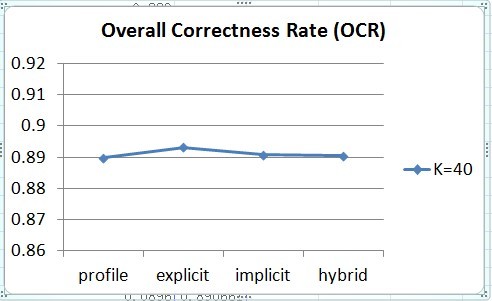
Figure 2. OCR of different attributes groups
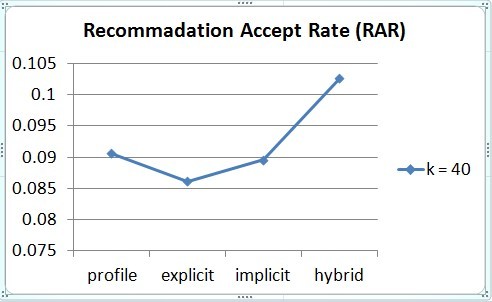
Figure 3. RAR of different attributes groups
Test for different K when considering the K most similar users
When we test our hybrid methods on different K. The OCR of the test (Figure 4) and the RAR (Figure 5) has similar results. K = 1 and large K tend to have better performance on both benchmarks. K = 10,20,30 have a lower correctness rate.
The running time for different K is almost the same - we will obviously do the sorting when K is not trivially small.
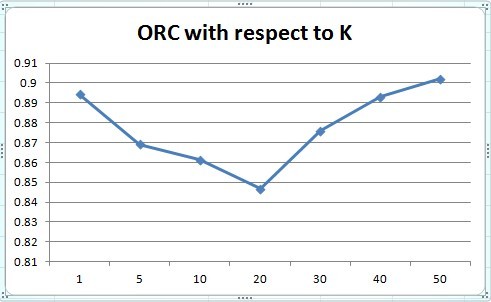
Figure 4. OCR of different K
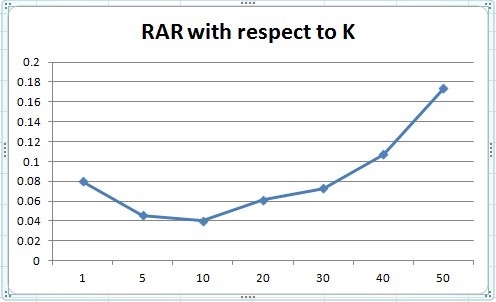
Figure 5. RAR of different K
4 Remaining Tasks
Find the better weights of hybrid method for more correct and effective prediction.
Get the result of subproblem 2: Predict the click-through rate of ads. (method : KNN regression+ metric learning)
Do more test and comparison on both problems and Analyze them.
5 References