Problem Statement:
Our objective for the project is to develop a recommender system that suggests songs to a user based on the songs currently in his/her playlist. We consider the user's playlist as a good indicator of the next song he/she might want to listen to. This would mean, given the contents of the playlist our recommender system should be able to provide suggestions to the playlist. For this purpose, would like to review and put to use some machine learning algorithms that suit our data.Progress:
As per our proposal goals, we are on track as we were able to complete the tasks of dataset shrinking, literature review, implementing and evaluating performance of different methods. Currently we’re able to look in the direction, which we believe will improve our results.-
To focus on the machine learning task and reduce the complexity of dealing with such a large dataset of 300GB, we used only a subset of the MillionSongDataset [1] consisting of 10,000 songs. The user listening history has 48 million user entries and out of those only 700,000 had listening history corresponding to our song subset. Working on this subset too proved computationally infeasible. Therefore, we finally considered a subset consisting of 4080 unique users and 1232 songs. Out of all the features provided by MillionSongDataset we consider the following 16 features which we find are useful.
Artist familiarity
Artist hotness
Artist ID
Location
Duration
Key
Key Confidence
Loudness
Mode
Mode confidence
Song ID
Tempo
Time Signature
Time Signature Confidence
Title
Year
Evaluation Criteria:
For evaluating the performance of our methods, we partitioned out listening history dataset into 3500 training set and 580 testing set. Our task was now to look at the first half of the listening history available and predict the remaining half. While partitioning the dataset, we also ensured that our test set contained users with atleast two songs in their playlist. We make top 10 song recommedations to the user to validate our results. We used mAP(mean Average Precision) to evaluate our recommendations as it gives importance to the relative rankings of the recommendations rather than just checking if the recommendation is a hit or miss. Higher mAP indicates better recommendation.
Implemented methods:
We have implemented one algorithm from each of the methods we intended to consider in our proposal. An outline of what we implemented is as follows.
Popularity : In this method we recommended to a user, the top 10 popular songs in the training set not in the user’s playlist.
For this method we got a mAP of 0.072685. We consider this as a baseline to evaluate our other methods.Collaborative Filtering(CF) : We implemented a version of both user-user and item-item CF methods. For implementing them we built a User-Item matrix UI for the training and testing set separately.
The entries of UI are binary. i.e. UI(i,j) = 1 if user i has played the song j and 0 otherwise.U/I
I1
I2
I3
…
In
U1
U2
1
…
…
1
Um
0
User-user CF : In this method, our measure of similarity between a two users was the cosine similarity. It is computed between the users i and j as:
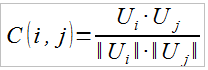

Results of this method for a varying k are presented below:
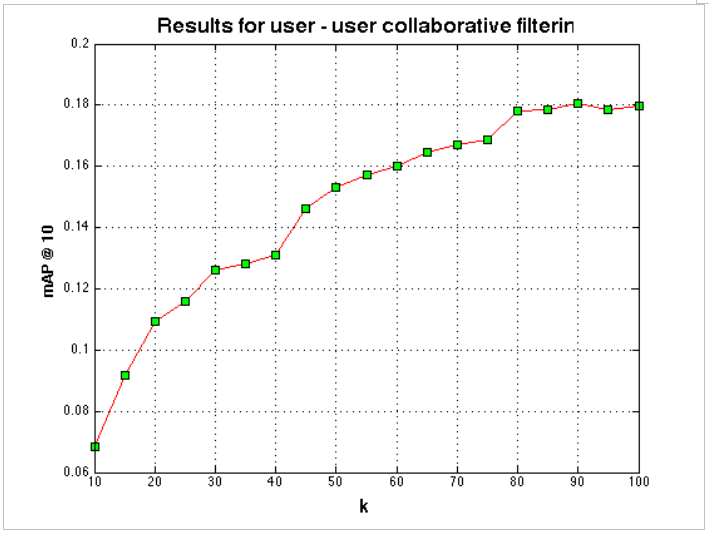
Fig. 1: mAP increasing with increasing k
Item – item CF : Akin to the user-user method we computed the cosine similarity between two songs i and j as:

Then top-k songs for every song in the test user’s playlist are selected and weighed, as done in user-user method. Top-10 songs from the aggregated list are recommended.
Results of this method for a varying k are as presented below:
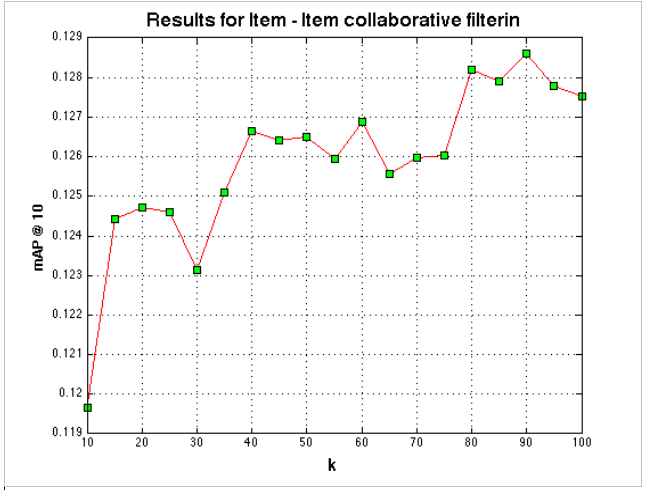
Fig. 2: mAP stable in the range 0.12-0.13
Content Based Filtering : We approached this as a binary classification method where the task is to predict if a user would label the song 1(to listen) or 0(to not listen). However, a problem we encountered with this approach is that to learn a user’s classification model, we needed more songs in the user’s playlist but our data had a majority of users’ playlists with less than 4 songs.
So currently we have implemented a simple method of grouping songs based on common features where we used a variant of the overlap coefficient[6] as a measure of similarity as our features (artists names, key, loudness, mode, tempo and year) were both nominal and numerical. The overlapping co-efficient is calculated as:

We then selected top-k similar songs and aggregated them with weights as done in CF methods and recommended top-10 songs.
Results of this method for a varying k are presented below:
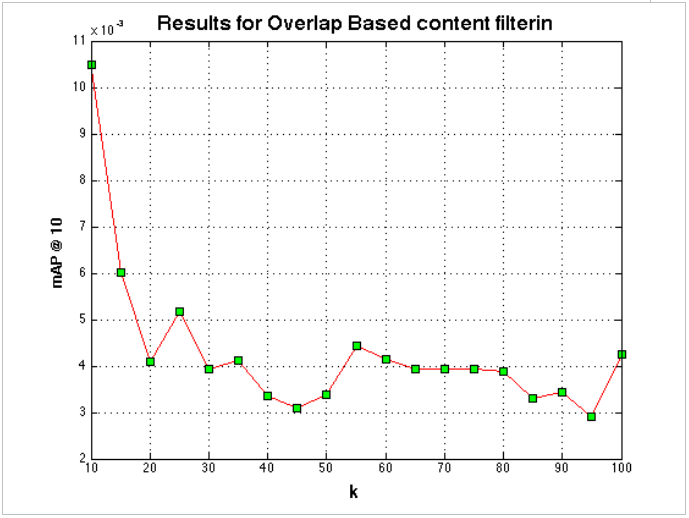
Fig. 3: Highest mAP of 0.01
Comparison of Results:
User-user CF showed improvement when more similar users were considered for recommendation, even reaching a mAP of 0.18.
Item-item CF seemed to remain stable in the mAP range of 0.12 to 0.13
Content based filtering failed to even meet our baseline consideration of 0.07 falling much short at 0.01. We believe poor feature selection might be the cause for this. We selected those features[8] that we thought affected song choice but low mAP and the drop in mAP with increasing k suggest otherwise.
Final Goals:
From our results, CF seems to be the better option but we would like to implement a hybrid of both CF and content based filtering methods.
Our goal for the next two weeks portion is to work out a better method for content filtering and use a combination of the methods to see if we can improve our current results.
Fine tuning our methods, poster presentation and final submission.
References:
[1] T. Bertin-Mahieux, D. Ellis, B. Whitman, and P. Lamere. The million song dataset. In Proceedings of the 11th International Society for Music Information Retrieval Conference (ISMIR 2011), 2011.[2] Brian McFee, Thierry Bertin-Mahieux, Daniel P.W. Ellis, and Gert R.G. Lanckriet, ‘The million song dataset challenge', in Proceedings of the 21st international conference companion on World Wide Web, WWW '12 Companion, pp. 909–916, New York, NY, USA, (2012). ACM
[3] Mukund Deshpande and George Karypis, ‘Item-based top-n recommendation algorithms', ACM Trans. Inf. Syst., 22(1), 143–177, (2004).
[4] Badrul M. Sarwar, George Karypis, Joseph A. Konstan, and John Riedl, ‘Item-based collaborative filtering recommendation algorithms', in WWW, pp. 285–295, (2001).
[5] Tianye Lu, Jing Xiong, Xiaoye Liu, Music Recommender System Utilizing Users’ Listening History and Social Network Information, Machine Learning Project Report, Stanford University.
[6] Claypool M, Gokhale A, and Miranda T, 'Combining content-based and collaborative filters in an online newspaper'. In Proceedings of the SIGIR-99 Workshop on Recommender Systems: Algorithms and Evaluation.
[7] Yoshinori Hijikata, Kazuhiro Iwahama, and Shogo Nishida. 2006. Content-based music filtering system with editable user profile. In Proceedings of the 2006 ACM symposium on Applied computing (SAC '06). ACM, New York, NY, USA, 1050-1057.
[8] Hung-Chen Chen and Arbee L. P. Chen. 2001. A music recommendation system based on music data grouping and user interests. In Proceedings of the tenth international conference on Information and knowledge management (CIKM '01), Henrique Paques, Ling Liu, and David Grossman (Eds.). ACM, New York, NY, USA, 231-238.