Armada: a parallel I/O framework for computational grids (1998-2006)
This project is no longer active; this page is no longer updated.
Related projects:
[CHARISMA],
[Galley],
[Parallel-I/O],
[RAPID-Transit],
[STARFISH]
Related keywords:
[pario],
[survey]
Summary
We developed the Armada parallel file system to allow a
programmer more flexibility in specifying how data could flow from a
set of I/O nodes to a set of computation nodes, in the context of
large-scale computational grids. In these grids, network latency is
significant, and it is important to pipeline the data flow. Armada
allows the programmer to specify the data-transformation operators
between the computation nodes and the I/O nodes, and internally
optimizes the structure before automatically deploying the operators
to intermediate nodes.
Objectives.
Develop an I/O framework that allows data-intensive applications
to efficiently access geographically distributed data sets.
Problem Definition.
An exciting trend in high-performance computing is the use of
geographically-distributed networks of heterogeneous systems and
devices known as "computational grids". Of particular interest is the
development of data-intensive grid applications. Data-intensive grid
applications require access to large (terabyte-petabyte) remote data
sets, and often require significant preprocessing of filtering before
the computation can take place. Such applications exist in many areas
of scientific computing including seismic processing, climate
modeling, particle physics, and others
Technical Approach.
The Armada framework for parallel I/O provides a solution for
data-intensive applications in which the application programmer and
data-set provider deploy a network of application-specific and
data-set-specific functionality across the grid. Using the Armada
framework, grid applications access remote data by sending data
requests through a graph of distributed application objects. A typical
graph consists of two distinct portions: one that describes the layout
of the data (as defined by the data provider), and one that describes
the interface and processing required by the application. Armada
appends the two portions to form a single graph, restructures the
resulting graph to distribute computation and data flow, and assigns
modules to grid processors so that data-reducing modules execute near
the data source and data-increasing modules execute near the data
destination. The figures below show the original and restructured
graphs for an application accessing a replicated and distributed data
set.
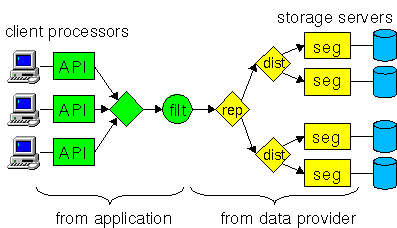
Figure 1: A typical Armada graph consists of a portion from the data provider
that describes the layout of the data and a portion from the application
that describes required preprocessing.
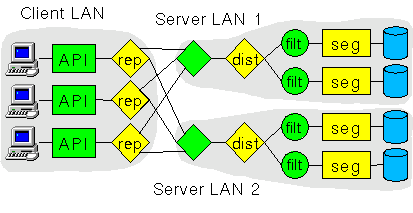
Figure 2: Armada restructured the graph to provide
end-to-end parallism and it moved the filter code close to the data
source. The grey blobs represent the three LANs used by the
application.
A key feature of Armada is the ability to restructure the
application graph. Unlike existing database systems that restructure
graphs based on well-known relational operators, Armada's
restructuring algorithm uses programmer-defined properties to allow
restructuring of a wide range of application classes (not just
relational databases).
Perhaps the most critical part of the Armada system is the
placement algorithm. Modules that make up the graph execute on
processors near the client, processors near the data, or intermediate
network processors. Our approach is to treat placement as a
hierarchical graph-partitioning problem. We first partition the graph
into domains in such a way to minimize the data transferred between
domains. Next, we partition the modules in each domain to available
processors provided by each domain's local resource manager.
Open Problems.
Armada is not a fully-featured I/O system. In particular, it lacks
support for data management, security, and fault tolerance, which are
necessary in a production grid system. While there are active research
groups working in each of these areas, there is still much debate over
proper solutions. In the Conclusions and Future Work section of the
dissertation (oldfield:thesis), we discuss the issues involved in
building support for each of these features in the Armada I/O system.
In addition, we present potential improvements to the placement
algorithm, and describe how to adapt Armada to work efficiently on
tightly-connected clusters of workstations.
Ron Oldfield and David Kotz.
Talks
Funding and acknowledgements
This research was funded by the
US Department of Energy (Sandia National Laboratories)
under contract DOE-AV6184.
The views and conclusions contained on this site and in its documents
are those of the authors and should not be interpreted as necessarily
representing the official position or policies, either expressed or
implied, of the sponsor(s). Any mention of specific companies or
products does not imply any endorsement by the authors or by the
sponsor(s).
Papers tagged 'armada'
[Also available in BibTeX]
Papers are listed in reverse-chronological order;
click an entry to pop up the abstract.
For full information and pdf, please click Details link.
Follow updates with RSS.

- 2006:
-
Ron Oldfield and David Kotz.
Improving data access for computational grid applications.
Cluster Computing.
January 2006.
[Details]
High-performance computing increasingly occurs on “computational grids” composed of heterogeneous and geographically distributed systems of computers, networks, and storage devices that collectively act as a single “virtual” computer. A key challenge in this environment is to provide efficient access to data distributed across remote data servers. Our parallel I/O framework, called Armada, allows application and data-set providers to flexibly compose graphs of processing modules that describe the distribution, application interfaces, and processing required of the dataset before computation. Although the framework provides a simple programming model for the application programmer and the data-set provider, the resulting graph may contain bottlenecks that prevent efficient data access. In this paper, we present an algorithm used to restructure Armada graphs that distributes computation and data flow to improve performance in the context of a wide-area computational grid.
- 2003:
-
Ron Oldfield.
Efficient I/O for Computational Grid Applications.
PhD thesis, May 2003.
Available as Dartmouth Computer Science Technical Report TR2003-459.
[Details]
High-performance computing increasingly occurs on “computational grids” composed of heterogeneous and geographically distributed systems of computers, networks, and storage devices that collectively act as a single “virtual” computer. A key challenge in this environment is to provide efficient access to data distributed across remote data servers. This dissertation explores some of the issues associated with I/O for wide-area distributed computing and describes an I/O system, called Armada, with the following features: a framework to allow application and dataset providers to flexibly compose graphs of processing modules that describe the distribution, application interfaces, and processing required of the dataset before or after computation; an algorithm to restructure application graphs to increase parallelism and to improve network performance in a wide-area network; and a hierarchical graph-partitioning scheme that deploys components of the application graph in a way that is both beneficial to the application and sensitive to the administrative policies of the different administrative domains. Experiments show that applications using Armada perform well in both low- and high-bandwidth environments, and that our approach does an exceptional job of hiding the network latency inherent in grid computing.
- 2002:
-
Ron Oldfield and David Kotz.
Using the Emulab network testbed to evaluate the Armada I/O framework for computational grids.
Technical Report, September 2002.
[Details]
This short report describes our experiences using the Emulab network testbed at the University of Utah to test performance of the Armada framework for parallel I/O on computational grids.
Ron Oldfield and David Kotz.
Armada: a parallel I/O framework for computational grids.
Future Generation Computing Systems (FGCS).
March 2002.
[Details]
High-performance computing increasingly occurs on “computational grids” composed of heterogeneous and geographically distributed systems of computers, networks, and storage devices that collectively act as a single “virtual” computer. One of the great challenges for this environment is to provide efficient access to data that is distributed across remote data servers in a grid. In this paper, we describe our solution, a framework we call Armada. Armada allows applications to flexibly compose modules to access their data, and to place those modules at appropriate hosts within the grid to reduce network traffic.
Ron Oldfield and David Kotz.
The Armada framework for parallel I/O on computational grids.
Proceedings of the USENIX Conference on File and Storage Technologies (FAST).
January 2002.
Work-in-progress report.
[Details]
- 2001:
-
Ron Oldfield and David Kotz.
Scientific Applications using Parallel I/O.
High Performance Mass Storage and Parallel I/O: Technologies and Applications.
September 2001.
[Details]
Scientific applications are increasingly being implemented on massively parallel supercomputers. Many of these applications have intense I/O demands, as well as massive computational requirements. This paper is essentially an annotated bibliography of papers and other sources of information about scientific applications using parallel I/O.
Ron Oldfield and David Kotz.
Armada: A parallel file system for computational grids.
Proceedings of the IEEE/ACM International Symposium on Cluster Computing and the Grid (ccGrid).
May 2001.
[Details]
High-performance distributed computing appears to be shifting away from tightly-connected supercomputers to computational grids composed of heterogeneous systems of networks, computers, storage devices, and various other devices that collectively act as a single geographically distributed virtual computer. One of the great challenges for this environment is providing efficient parallel data access to remote distributed datasets. In this paper, we discuss some of the issues associated with parallel I/O and computatational grids and describe the design of a flexible parallel file system that allows the application to control the behavior and functionality of virtually all aspects of the file system.
- 1998:
-
Ron Oldfield and David Kotz.
Applications of Parallel I/O.
Technical Report, August 1998.
Supplement to PCS-TR96-297.
[Details]
Scientific applications are increasingly being implemented on massively parallel supercomputers. Many of these applications have intense I/O demands, as well as massive computational requirements. This paper is essentially an annotated bibliography of papers and other sources of information about scientific applications using parallel I/O. It will be updated periodically.
- 1996:
-
David Kotz.
Applications of Parallel I/O.
Technical Report, October 1996.
Release 1.
[Details]
Scientific applications are increasingly being implemented on massively parallel supercomputers. Many of these applications have intense I/O demands, as well as massive computational requirements. This paper is essentially an annotated bibliography of papers and other sources of information about scientific applications using parallel I/O. It will be updated periodically.
[Kotz research]