
Next: Approach
Up: Increasing the I.Q. of
Previous: Increasing the I.Q. of
We now live in an ``age of information'', and arguably, communications
serve as its motive force [3]. As participants
in this age, we rely on cheap, ubiquitous, and reliable computers and
communications to forward goals in our daily lives. Digital devices
such as PDAs, laptops, and smartphones serve as our interface to this
information-rich, electronic world.
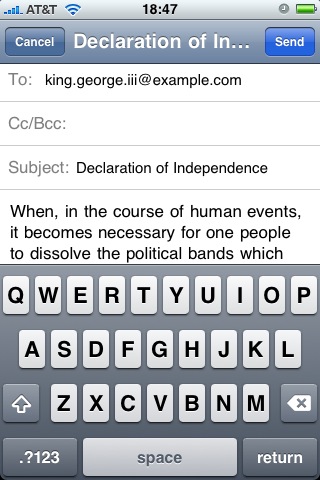
In this world, many people have experienced typing an email on a
smartphone keyboard such as the one depicted in
Figure 1. A small keyboard and context-insensitive
typing corrections lead to errors and a poor email experience. These
devices require users to conform to their interfaces rather than the
converse.
Figure 1:
Email on the iPhone. Usabliity lacks despite the
keyboard's QWERTY layout and email application's spelling
suggestions. The suggestions lack context to prior emails and in
addition, typing small letters with large fingers creates
frustration. Some smartphones have tactile keyboards which do
not fix these usability problems.
|
|
In this work, we will address the problem of unusable email by
creating a machine learning (ML) model that accurately predicts ``the
next word'' as a user types her email. We hypothesize that word
prediction will provide a significant reduction in keystrokes for the
following reasons: users have consistency in writing style, topics,
and the identity of message recipients; a properly chosen learning
algorithm can capture these similarities; and many users have a
significant email corpus on which a learning algorithm can be trained.
To make email usable on a smartphone, we plan to use the following
approach:
- We will focus our efforts on designing a suitable prediction
model, as opposed to, for example, intregrating the model with an
existing email application.
- As we build and refine the model, we will use a fraction of our
personal email accounts as training datasets. This approach mirrors
how one would use our model in practice.
- Finally, we will analyze its performance against the remaining
fraction of personal email left out during training.
In the rest of this paper, we present more details of our proposal.
We outine our approach in Section 2, describe the source
of our training and testing data sets in Section 3,
and present a rough project schedule in Section 4.
Next: Approach
Up: Increasing the I.Q. of
Previous: Increasing the I.Q. of
jac
2010-04-13