

Next: Dataset Sanity Check
Up: Dataset
Previous: Dataset
Preprocessing
Preprocessing email was not straightforward. The goal was to capture
typed text, no more, and no less. Unfortunately, many messages
contained forwarded or reply-to components in special formats. For
example, the character ``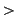 '' at the beginning of a line typically
refers to a reply-to text that should be ignored. In other special
cases, constructions such as ``:)'' refer to valid typed text (i.e.,
emoticons). For these reasons, we preferred to forgo filtering
punctuation and stop and stemming words--we want to account for
frequently typed text and have not measured the impact of such
filtering on the performance of our system.
'' at the beginning of a line typically
refers to a reply-to text that should be ignored. In other special
cases, constructions such as ``:)'' refer to valid typed text (i.e.,
emoticons). For these reasons, we preferred to forgo filtering
punctuation and stop and stemming words--we want to account for
frequently typed text and have not measured the impact of such
filtering on the performance of our system.
In addition, some email messages contain HTML from web-based email
systems, and others contain base64 encoded objects such as pictures.
Some messages contain signatures with long strings of ``*'', ``-'', or
``='' characters. We did not attempt to handle perfectly all these
special cases (and more). Rather, to address a majority of the
issues, we used regular expressions such as the ones shown in
Figures 1 and 2 to define
which lines to skip and which characters to strip before computing
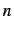 -grams. In some cases, we stripped away or ignored too much text
and in others, too little.
-grams. In some cases, we stripped away or ignored too much text
and in others, too little.
Figure 1:
Regular expression used to skip text. Many messages
include the string ``Original Message'', headers, and lines
prefixed with ``
'' because the message is a reply to another
message. Others include base64 encoded text. These expressions
allow the script to ignore such lines.
![\begin{figure}\begin{verbatim}(^From:)\vert(^Date:)\vert(^Subject:)\vert
(^To:...
...t
(^[0-9A-za-z+/]{30,}$)\vert
(^[0-9A-Za-z+/]+[=]*\$)\end{verbatim}
\end{figure}](img18.png) |
Figure 2:
Regular expression used to stip text. In some cases,
messages include symbols or text that a user doesn't type, but the
text exists in a line with user typed text. These expressions
strip such non-typed characters.
![\begin{figure}\begin{verbatim}([<>,'']+)\vert(\w@\w)\vert([*]{2,})\vert
(\[mailto:.*\])\vert([-_]{2,})\end{verbatim}
\end{figure}](img19.png) |
Finally, we track each message recipient set, which includes names
listed with the following address fields: ``Cc'', ``Bcc'', and ``To''.
Each address can contain an alias and an email address as in
``Joseph Cooley'' 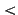 jac@cs.dartmouth.edu
.
jac@cs.dartmouth.edu
.
In some cases, the alias is a duplicate address of the
one it precedes, as in the following:
``jac@cs.dartmouth.edu''
jac@cs.dartmouth.edu
.
We prevent cases like these from introducing duplicate
addresses within our data structures by maintaining the recipient list
in a python ``set'' structure. A python set functions as a
mathematical set; it does not store duplicates.
Next: Dataset Sanity Check
Up: Dataset
Previous: Dataset
jac
2010-05-11