

Next: Preprocessing
Up: Increasing the I.Q. of
Previous: Introduction
Dataset
We built our dataset using the sent mailbox from our gmail account.
In total, the account contains nearly 1.4 GB of email total,
approximately 500 MB of which corresponds to sent mail. The volume
includes email headers, subject lines, message bodies, attachments,
and any message content typed by others such as forwarded messages or
reply-to text.
We fetched email from gmail using using a python script and the secure
IMAP protocol1. Python
includes modules for IMAP, SSL (used to secure IMAP), regular
expression processing, and email processing, which we used extensively
to build our dataset. Gmail transmitted each message in raw RFC822
format, which our script received and stored in a sqlite database.
Then, we ran a separate python script to strip away all but message
bodies from each message. A third script computed 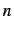 -grams on each
of the bodies, where
-grams on each
of the bodies, where
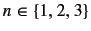 , and
Table 1 shows the vocabulary size and number of
samples associated with each
-gram set.
, and
Table 1 shows the vocabulary size and number of
samples associated with each
-gram set.
Table 1:
Dataset statistics for 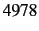 emails from our
gmail sent mailbox. The statistics are computed after
preprocessing that includes stripping away message headers,
attachments, and forwarded or reply-to message components.
Preprocessing reduces signficantly the size of our dataset
from
emails from our
gmail sent mailbox. The statistics are computed after
preprocessing that includes stripping away message headers,
attachments, and forwarded or reply-to message components.
Preprocessing reduces signficantly the size of our dataset
from
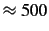 MB to
MB to 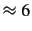 MB.
MB.
|
-gram Type |
Vocabulary Size |
# of Samples |
| unigram |
59386 |
910812 |
| bigram |
268665 |
905937 |
| trigram |
422433 |
901314 |
|
Subsections
Next: Preprocessing
Up: Increasing the I.Q. of
Previous: Introduction
jac
2010-05-11