

Next: Dataset
Up: Increasing the I.Q. of
Previous: Increasing the I.Q. of
Introduction
In this work, we proposed to reduce the number of keystrokes required
to write email on mobile devices such as smartphones. Existing
devices can provide a frustrating user experience because they include
small keyboards and context-insensitive typing corrections, which lead
to errors and a poor email experience. We proposed to use our
personal email as a source for both training and testing a model
that predicts accurately the next typed word.
Our initial research suggested that we use a Markov model to compute
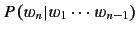 , where
, where 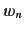 is the
is the 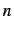 th word of an
-gram model and that the Good-Turing method [2] may
provide a suitable means for smoothing probability mass among seen and
unseen
-grams before predicting words.
th word of an
-gram model and that the Good-Turing method [2] may
provide a suitable means for smoothing probability mass among seen and
unseen
-grams before predicting words.
In summary, we have completed the following tasks and appear to be
slightly ahead of schedule.
- Collect, parse, and split email bodies into
-grams, and
compute statistics for use in the prediction model.
- Create the Markov-based, word prediction model.
- Analyze model performance and productivity increase in writing
emails.
In the rest of this document, we will describe the status of our
research. In Section 2 we discuss the dataset, its
origin, characteristics, and preprocessing. Then, in
Section 3 we discuss the probability mass estimator
used to smooth
-gram distributions and the technique used to
predict words. In Section 4 we begin to analyze
the performance of our approach, and in Section 5 we
conclude by reviewing the schedule.
Next: Dataset
Up: Increasing the I.Q. of
Previous: Increasing the I.Q. of
jac
2010-05-11