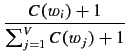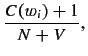In 1995, Gale and Sampson published the Simple Good-Turing model with
an algorithm, sample data, and code for the
estimator [2]. Our work relies on Sampon's C
code [8] and a python script we wrote to manage ![]() -grams
and compute word predictions. The original Good-Turing estimator was
developed by Alan Turing and an assistant I. J. Good while they worked
at Beltchley Park to crack the German Enigma cipher during World War
II [5].
-grams
and compute word predictions. The original Good-Turing estimator was
developed by Alan Turing and an assistant I. J. Good while they worked
at Beltchley Park to crack the German Enigma cipher during World War
II [5].
The estimator deals with frequencies of frequencies of events and was designed to smooth a probability distribution in such a way that it accounts reasonably for events that have not occurred. A standard machine learning practice called Maximum Likelihood Estimation (MLE) does not work suitably for word prediction because it assigns probability mass solely to seen events. As we demonstrate next for unigrams, MLE neglects unseen events2:
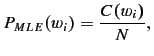
where the probability of a word
Add-one or Laplace smoothing as shown in equation 1 and
seen in class, adds one to estimation components to account for unseen
events. Unfortunately, it takes away too much probability mass from
seen events and adds to much to unseen events.
Simple Good-Turing apportions probability mass to unseen events by
using mass associated with events that occur 1 time. All events that
occur ![]() times are reassigned probability mass associated with events
that occur
times are reassigned probability mass associated with events
that occur ![]() times.
times.
To make this notion concrete, consider Table 2
which contains a sample of unigram frequencies from our dataset. If
we define the total number of words in the dataset as
![]() and use Good-Turning to compute the total probability of all unseen
events as
and use Good-Turning to compute the total probability of all unseen
events as ![]() , then the total probability of all unseen events in
our unigram dataset is
, then the total probability of all unseen events in
our unigram dataset is
![]() .
.
The goal, then, in Good-Turing is to compute the probability for
events seen ![]() times as
times as
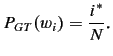
The trick is to compute
![$\displaystyle i^* = (i+1)\frac{\mathbb{E}\mbox{[}N_{i+1}\mbox{]}}{\mathbb{E}\mbox{[}N_i\mbox{]}} \mbox{\cite{church1991appendix}}
$](img39.png)
When ![]() is large (at lower frequencies) it represents a better
measurement. In these cases, we replace
is large (at lower frequencies) it represents a better
measurement. In these cases, we replace
![]() [
[![]() ]
with
]
with ![]() and call
and call
![]() a Turing estimator [3]. Small values of
a Turing estimator [3]. Small values of
![]() represent poor measurements with much noise, and so replacing
represent poor measurements with much noise, and so replacing
![]() [
[![]() ]
with
]
with ![]() is a poor choice. In these cases, we replace
is a poor choice. In these cases, we replace
![]() [
[![]() ]
with a smoothed estimate
]
with a smoothed estimate ![]() as suggested by
Good [4] and call
as suggested by
Good [4] and call ![]() according to the
smoothing function used. Table 2 shows noise in
our dataset as
according to the
smoothing function used. Table 2 shows noise in
our dataset as ![]() increases:
increases: ![]() oscillates at lower values.
oscillates at lower values.
At this point, the problem of smoothing boils down to choosing a good
smoothing function and deciding when to switch between using ![]() and
the smoothing function. For the function, we use
and
the smoothing function. For the function, we use
![]() defined by Gale and
Sampson [2]. The value of
defined by Gale and
Sampson [2]. The value of ![]() is learned using linear
regression. Gale and Sampson call the associated Good-Turing estimate
the Linear Good-Turing estimate (LGT) and a renormalized version of
LGT in combination with the Turing-estimator, Simple Good-Turing
(SGT). Note that once the C-code begins using the smoothing function,
it continues to do so.
is learned using linear
regression. Gale and Sampson call the associated Good-Turing estimate
the Linear Good-Turing estimate (LGT) and a renormalized version of
LGT in combination with the Turing-estimator, Simple Good-Turing
(SGT). Note that once the C-code begins using the smoothing function,
it continues to do so.