

Next: Analysis
Up: Estimation Algorithm
Previous: Estimation Algorithm
So far, we have discussed smoothing a probability mass using Simple
Good-Turing. After computing smooth mass values, we compute the
following using them. Our word prediction is associated with the
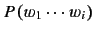 that maximizes the following equation.
that maximizes the following equation.
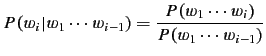 |
(2) |
jac
2010-05-11